hyperloglog算法,利用非常少的空间,实现比较大的数据量级统计;比如我们前面在介绍bitmap的过程中,说到了日活的统计,当数据量达到百万时,最佳的存储方式是hyperloglog,本文将介绍一下hyperloglog的基本原理,以及redis中的使用姿势
I. 基本使用
1. 配置
我们使用SpringBoot 2.2.1.RELEASE来搭建项目环境,直接在pom.xml中添加redis依赖
1 | <dependency> |
如果我们的redis是默认配置,则可以不额外添加任何配置;也可以直接在application.yml配置中,如下
1 | spring: |
2. 使用姿势
我们下来看使用姿势,原理放在后面说明
redis中,hyperlolog使用非常简单,一般就两个操作命令,添加pfadd + 计数pfcount;另外还有一个不常用的merge
a. add
添加一条记录
1 | public boolean add(String key, String obj) { |
b. pfcount
非精准的计数统计
1 | public long count(String key) { |
a. merge
将多个hyperloglog合并成一个新的hyperloglog;感觉用的场景并不会特别多
1 | public boolean merge(String out, String... key) { |
3. 原理说明
关于HyperLogLog的原理我这里也不进行详细赘述,说实话那一套算法以及调和平均公式我自己也没太整明白;下面大致说一下我个人的朴素理解
Redis中的HyperLogLog一共分了2^14=16384个桶,每个桶占6个bit
一个数据,塞入HyperLogLog之前,先hash一下,得到一个64位的二进制数据
- 取低14位,用来定位桶的index
- 高50位,从低到高数,找到第一个为1出现的位置n
- 若桶中值 > n,则丢掉
- 反之,则设置桶中的值为n
那么怎么进行计数统计呢?
- 拿所有桶中的值,代入下面的公式进行计算
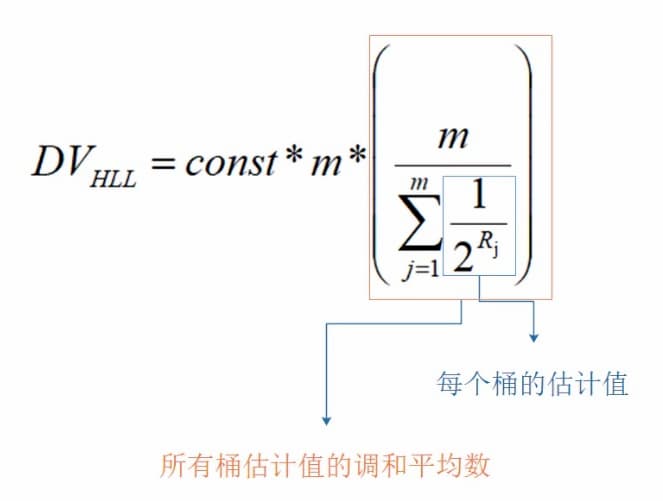
上面这个公式怎么得出的?
之前看到一篇文章,感觉不错,有兴趣了解原理的,可以移步: https://www.jianshu.com/p/55defda6dcd2
4. 应用场景
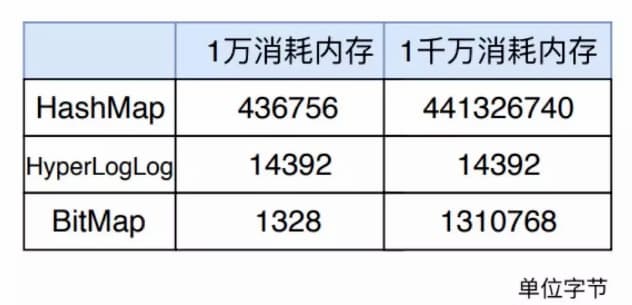
hyperloglog通常是用来非精确的计数统计,前面介绍了日活统计的case,当时使用的是bitmap来作为数据统计,然而当userId分散不均匀,小的特别小,大的特别大的时候,并不适用
在数据量级很大的情况下,hyperloglog的优势非常大,它所占用的存储空间是固定的2^14
下图引用博文《用户日活月活怎么统计》
使用HyperLogLog进行日活统计的设计思路比较简单
- 每日生成一个key
- 某个用户访问之后,执行
pfadd key userId - 统计总数:
pfcount key
II. 其他
0. 项目
系列博文
- 【DB系列】Redis高级特性之发布订阅
- 【DB系列】Redis高级特性之Bitmap使用姿势及应用场景介绍
- 【DB系列】Redis之管道Pipelined使用姿势
- 【DB系列】Redis集群环境配置
- 【DB系列】借助Redis搭建一个简单站点统计服务(应用篇)
- 【DB系列】借助Redis实现排行榜功能(应用篇)
- 【DB系列】Redis之ZSet数据结构使用姿势
- 【DB系列】Redis之Set数据结构使用姿势
- 【DB系列】Redis之Hash数据结构使用姿势
- 【DB系列】Redis之List数据结构使用姿势
- 【DB系列】Redis之String数据结构的读写
- 【DB系列】Redis之Jedis配置
- 【DB系列】Redis之基本配置
工程源码
- 工程:https://github.com/liuyueyi/spring-boot-demo
- 项目源码: https://github.com/liuyueyi/spring-boot-demo/tree/master/spring-boot/122-redis-template
1. 一灰灰Blog
尽信书则不如,以上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现bug或者有更好的建议,欢迎批评指正,不吝感激
下面一灰灰的个人博客,记录所有学习和工作中的博文,欢迎大家前去逛逛
- 一灰灰Blog个人博客 https://blog.hhui.top
- 一灰灰Blog-Spring专题博客 http://spring.hhui.top


