2.JPA之新增记录使用姿势
上一篇文章介绍了如何快速的搭建一个JPA的项目环境,并给出了一个简单的演示demo,接下来我们开始业务教程,也就是我们常说的CURD,接下来进入第一篇,如何添加数据
通过本篇文章,你可以get到以下技能点
- POJO对象如何与表关联
- 如何向DB中添加单条记录
- 如何批量向DB中添加记录
- save 与 saveAndFlush的区别
I. 环境准备
实际开始之前,需要先走一些必要的操作,如安装测试使用mysql,创建SpringBoot项目工程,设置好配置信息等,关于搭建项目的详情可以参考前一篇文章 190612-SpringBoot系列教程JPA之基础环境搭建
下面简单的看一下演示添加记录的过程中,需要的配置
1. 表准备
沿用前一篇的表,结构如下
CREATE TABLE `money` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL DEFAULT '' COMMENT '用户名',
`money` int(26) NOT NULL DEFAULT '0' COMMENT '钱',
`is_deleted` tinyint(1) NOT NULL DEFAULT '0',
`create_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
2. 项目配置
配置信息,与之前有一点点区别,我们新增了更详细的日志打印;本篇主要目标集中在添加记录的使用姿势,对于配置说明,后面单独进行说明
## DataSource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/story?useUnicode=true&characterEncoding=UTF-8&useSSL=false
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.username=root
spring.datasource.password=
## jpa相关配置
spring.jpa.database=MYSQL
spring.jpa.hibernate.ddl-auto=none
spring.jpa.show-sql=true
spring.jackson.serialization.indent_output=true
spring.jpa.hibernate.naming.physical-strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
II. Insert使用教程
在开始之前,先声明一下,因为个人实际项目中并没有使用到JPA,对JPA的原则和hibernate的一些特性了解的也不多,目前处于学习探索阶段,主要是介绍下使用姿势,下面的东西都是经过测试得出,有些地方描述可能与规范不太一样,或者有些差错,请发现的大佬指正
接下来我们进入正题,如何通过JPA实现我们常见的Insert功能
1. POJO与表关联
首先第一步就是将POJO对象与表关联起来,这样就可以直接通过java的操作方式来实现数据库的操作了;
我们直接创建一个MoneyPo对象,包含上面表中的几个字段
@Data
public class MoneyPO {
private Integer id;
private String name;
private Long money;
private Byte isDeleted;
private Timestamp createAt;
private Timestamp updateAt;
}
自然而然地,我们就有几个问题了
- 这个POJO怎么告诉框架它是和表Money绑定的呢?
- Java中变量命令推荐驼峰结构,那么
isDeleted又如何与表中的is_deleted关联呢? - POJO中成员变量的类型如何与表中的保持一致呢,如果不一致会怎样呢?
针对上面的问题,一个一个来说明
对hibernate熟悉的同学,可能知道我可以通过xml配置的方式,来关联POJO与数据库表(当然mybatis也是这么玩的),友情链接一下hibernate的官方说明教程;我们使用SpringBoot,当然是选择注解的方式了,下面是通过注解的方式改造之后的DO对象
package com.git.hui.boot.jpa.entity;
import lombok.Data;
import org.springframework.data.annotation.CreatedDate;
import javax.persistence.*;
import java.sql.Timestamp;
/**
* Created by @author yihui in 21:01 19/6/10.
*/
@Data
@Entity(name="money")
public class MoneyPO {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Integer id;
@Column(name = "name")
private String name;
@Column(name = "money")
private Long money;
@Column(name = "is_deleted")
private Byte isDeleted;
@Column(name = "create_at")
@CreatedDate
private Timestamp createAt;
@Column(name = "update_at")
@CreatedDate
private Timestamp updateAt;
}
有几个有意思的地方,需要我们注意
a. entity注解
@Entity 这个注解比较重要,用于声明这个POJO是一个与数据库中叫做 money 的表关联的对象;
@Entity注解有一个参数name,用于指定表名,如果不主动指定时,默认用类名,即上面如果不指定那么,那么默认与表moneypo绑定
另外一个常见的方式是在类上添加注解 @Table,然后指定表名,也是可以的
@Data
@Entity
@Table(name = "money")
public class MoneyPO {
}
b. 主键指定
我们可以看到id上面有三个注解,我们先看下前面两个
@Id顾名思义,用来表明这家伙是主键,比较重要,需要特殊关照@GeneratedValue设置初始值,谈到主键,我们一般会和”自增“这个一起说,所以你经常会看到的取值为strategy = GenerationType.IDENTITY(由数据库自动生成)
这个注解主要提供了四种方式,分别说明如下
| 取值 | 说明 |
|---|---|
GenerationType.TABLE | 使用一个特定的数据库表格来保存主键 |
GenerationType.SEQUENCE | 根据底层数据库的序列来生成主键,条件是数据库支持序列 |
GenerationType.IDENTITY | 主键由数据库自动生成(主要是自动增长型) |
GenerationType.AUTO | 主键由程序控制 |
关于这几种使用姿势,这里不详细展开了,有兴趣的可以可以看一下这博文: @GeneratedValue
c. Column注解
这个注解就是用来解决我们pojo成员名和数据库列名不一致的问题的,这个注解内部的属性也不少,相对容易理解,后面会单开一章来记录这些常用注解的说明查阅
d. CreateDate注解
这个注解和前面不一样的是它并非来自jpa-api包,而是spring-data-common包中提供的,表示会根据当前时间创建一个时间戳对象
e. 其他
到这里这个POJO已经创建完毕,后续的表中添加记录也可以直接使用它了,但是还有几个问题是没有明确答案的,先提出来,期待后文可以给出回答
- POJO属性的类型与表中类型
- mysql表中列可以有默认值,这个在POJO中怎么体现
- 一个表包含另一个表的主键时(主键关联,外键)等特殊的情况,POJO中有体现么?
2. Repository API声明
jpa非常有意思的一点就是你只需要创建一个接口就可以实现db操作,就这么神奇,可惜本文里面见不到太多神奇的用法,这块放在查询篇来见证奇迹
我们定义的API需要继承自org.springframework.data.repository.CrudRepository,如下
package com.git.hui.boot.jpa.repository;
import com.git.hui.boot.jpa.entity.MoneyPO;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.repository.CrudRepository;
/**
* 新增数据
* Created by @author yihui in 11:00 19/6/12.
*/
public interface MoneyCreateRepository extends CrudRepository<MoneyPO, Integer> {
}
好的,到这里就可以直接添加数据了 (感觉什么都没干,你居然告诉我可以插入数据???)
3. 使用姿势
a. 基础使用case
常规的使用姿势,无非单个插入和批量插入,我们先来看一下常规操作
@Component
public class JpaInsertDemo {
@Autowired
private MoneyCreateRepository moneyCreateRepository;
public void testInsert() {
addOne();
addMutl();
}
private void addOne() {
// 单个添加
MoneyPO moneyPO = new MoneyPO();
moneyPO.setName("jpa 一灰灰");
moneyPO.setMoney(1000L);
moneyPO.setIsDeleted((byte) 0x00);
Timestamp now = new Timestamp(System.currentTimeMillis());
moneyPO.setCreateAt(now);
moneyPO.setUpdateAt(now);
MoneyPO res = moneyCreateRepository.save(moneyPO);
System.out.println("after insert res: " + res);
}
private void addMutl() {
// 批量添加
MoneyPO moneyPO = new MoneyPO();
moneyPO.setName("batch jpa 一灰灰");
moneyPO.setMoney(1000L);
moneyPO.setIsDeleted((byte) 0x00);
Timestamp now = new Timestamp(System.currentTimeMillis());
moneyPO.setCreateAt(now);
moneyPO.setUpdateAt(now);
MoneyPO moneyPO2 = new MoneyPO();
moneyPO2.setName("batch jpa 一灰灰");
moneyPO2.setMoney(1000L);
moneyPO2.setIsDeleted((byte) 0x00);
moneyPO2.setCreateAt(now);
moneyPO2.setUpdateAt(now);
Iterable<MoneyPO> res = moneyCreateRepository.saveAll(Arrays.asList(moneyPO, moneyPO2));
System.out.println("after batchAdd res: " + res);
}
}
看下上面的两个插入方式,就这么简单,
- 通过IoC/DI注入 repository
- 创建PO对象,然后调用
save,saveAll方法就ok了
上面是一般的使用姿势,那么非一般使用姿势呢?
b. 插入时默认值支持方式
在创建表的时候,我们知道字段都有默认值,那么如果PO对象中某个成员我不传,可以插入成功么?会是默认的DB值么?
private void addWithNull() {
// 单个添加
try {
MoneyPO moneyPO = new MoneyPO();
moneyPO.setName("jpa 一灰灰 ex");
moneyPO.setMoney(2000L);
moneyPO.setIsDeleted(null);
MoneyPO res = moneyCreateRepository.save(moneyPO);
System.out.println("after insert res: " + res);
} catch (Exception e) {
System.out.println("addWithNull field: " + e.getMessage());
}
}
当看到上面的try/catch可能就有预感,上面的执行多半要跪(😏😏😏),下面是执行截图,也是明确告诉了我们这个不能为null
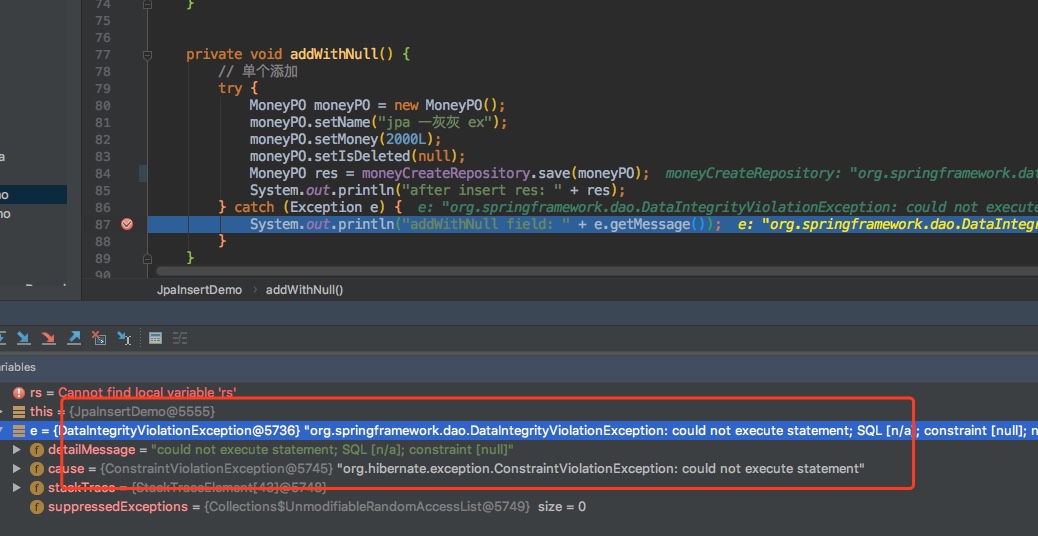
那么有办法解决么?难道就这么向现实放弃,向大佬妥协么?
默认值嘛,一个很容易想到的方法,我直接在PO对象中给一个默认值,是不是也可以,然后我们的PO改造为
@Data
@Entity
@Table(name = "money")
public class MoneyPO {
// ... 省略其他
@Column(name = "is_deleted")
private Byte isDeleted = (byte) 0x00;
}
测试代码注释一行,变成下面这个
private void addWithNull() {
// 单个添加
try {
MoneyPO moneyPO = new MoneyPO();
moneyPO.setName("jpa 一灰灰 ex");
moneyPO.setMoney(2000L);
// moneyPO.setIsDeleted(null);
MoneyPO res = moneyCreateRepository.save(moneyPO);
System.out.println("after insert res: " + res);
} catch (Exception e) {
System.out.println("addWithNull field: " + e.getMessage());
}
}
再次执行看下结果如何,顺利走下去,没有报错,喜大普奔
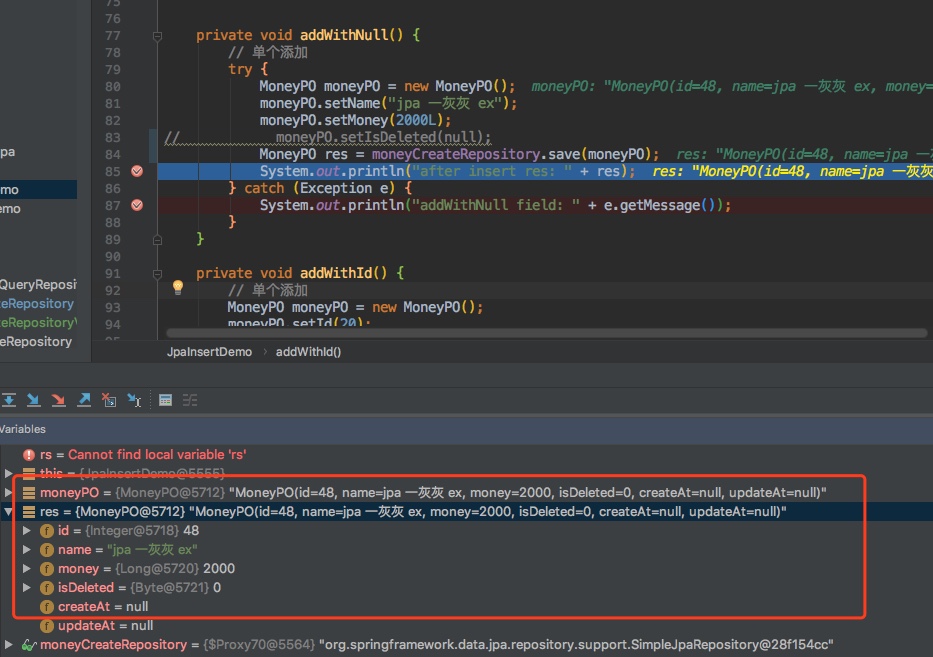
这样我就满足了吗?要是手抖上面测试注释掉的那一行忘了注释,岂不是依然会跪?而且我希望是表中的默认值,直接在代码中硬编码会不会不太优雅?这个主动设置的默认值,在后面查询的时候会不会有坑?
- 作为一个有追求的新青年,当然对上面的答案say no了
我们的解决方法也简单,在PO类上,加一个注解 @DynamicInsert,表示在最终创建sql的时候,为null的项就不要了哈
然后我们的新的PO,在原始版本上变成如下(注意干掉上一次的默认值)
@Data
@DynamicInsert
@Entity
@Table(name = "money")
public class MoneyPO {
// ... 省略
}
再来一波实际的测试,完美了,没有抛异常,插入成功,而且控制台中输出的sql日志也验证了我们上面说的@DynamicInsert注解的作用(日志输出hibernate的sql,可以通过配置application.properties文件,添加参数spring.jpa.show-sql=true)
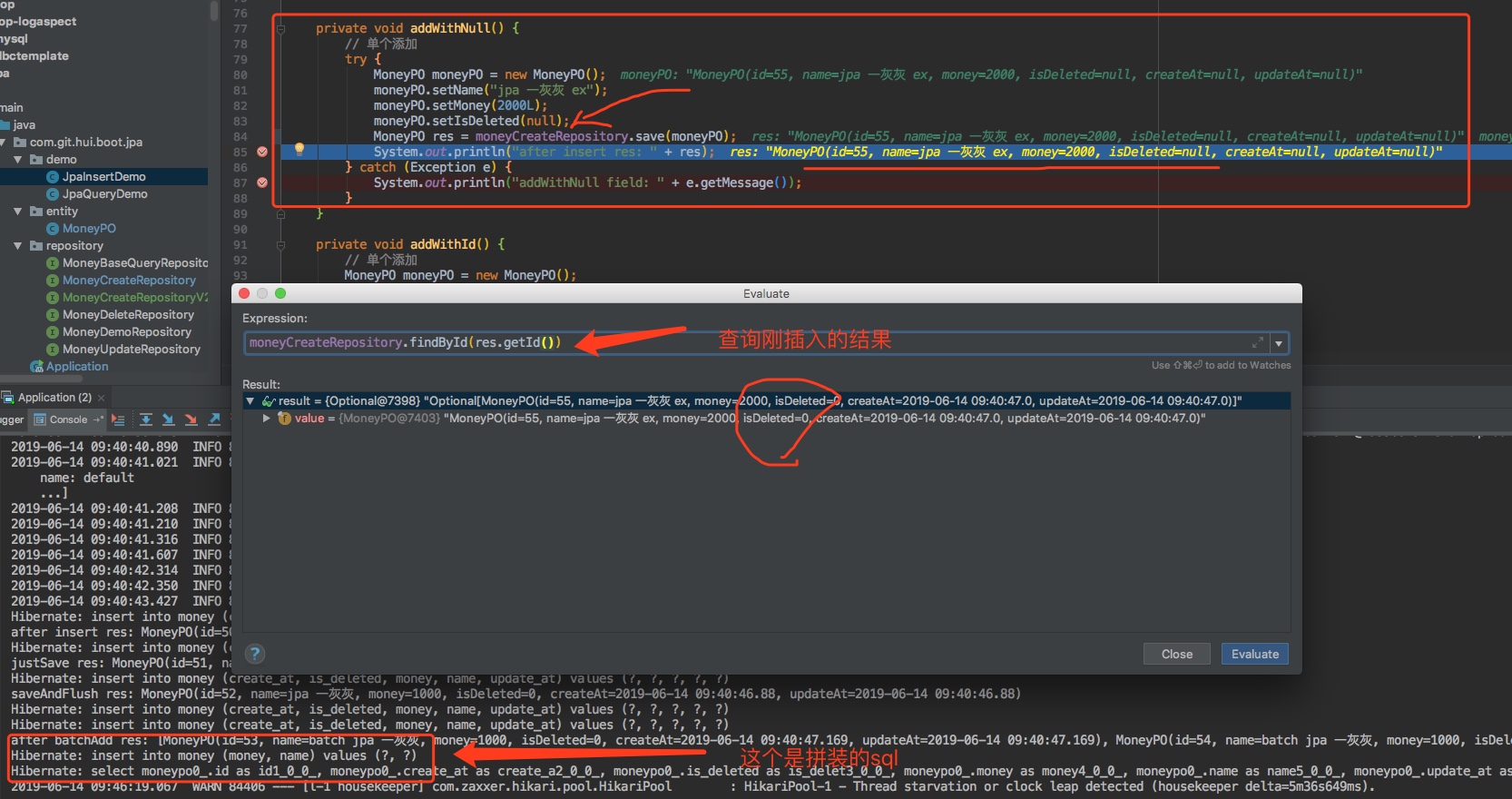
c. 类型关联
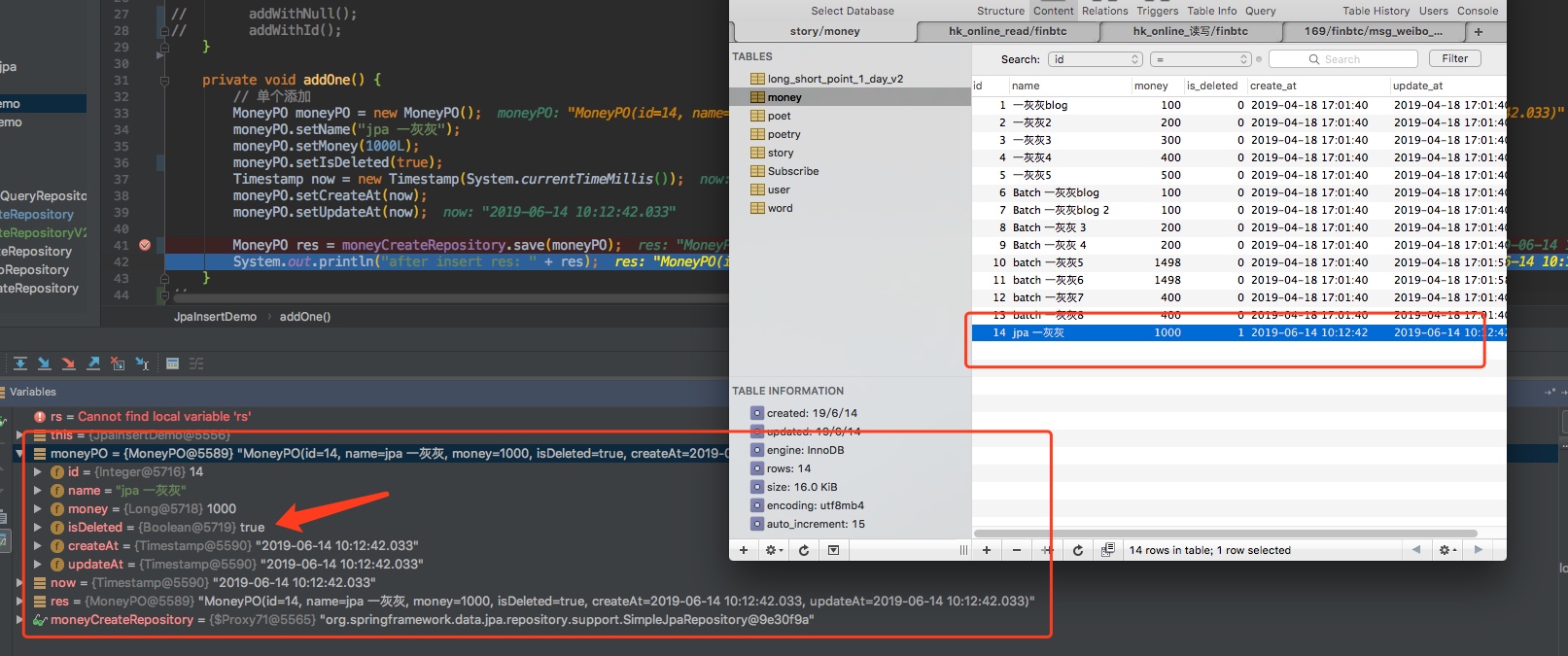
针对上面的PO对象,有几个地方感觉不爽,isDelete我想要boolean,true表示删除false表示没删除,搞一个byte用起来太不方便了,这个要怎么搞?
这个并不怎么复杂,因为直接将byte类型改成boolean就可以了,如果db中时0对应的false;1对应的true,下面是验证结果,并没有啥问题
在JPA规范中,并不是所有的类型的属性都可以持久化的,下表列举了可映射为持久化的属性类型:
| 分类 | 类型 |
|---|---|
| 基本类型 | byte、int、short、long、boolean、char、float、double |
| 基本类型封装类 | Byte、Integer、Short、Long、Boolean、Character、Float、Double |
| 字节和字符数组 | byte[]、Byte[]、char[]、Character[] |
| 大数值类型 | BigInteger、BigDecimal |
| 字符串类型 | String |
| 时间日期类 | java.util.Date、java.util.Calendar、java.sql.Date、java.sql.Time、java.sql.Timestamp |
| 集合类 | java.util.Collection、java.util.List、java.util.Set、java.util.Map |
| 枚举类型 | |
| 嵌入式 |
关于类型关联,在查询这一篇会更详细的进行展开说明,比如有个特别有意思的点
如db中is_delete为1,需要映射到PO中的false,0映射到true,和我们上面默认的是个反的,要怎么搞?
d. 插入时指定ID
再插入的时候,我们上面的case都是没有指定id的,但是如果你指定了id,会发生什么事情?
我们将po恢复到之前的状态,测试代码如下
private void addWithId() {
// 单个添加
MoneyPO moneyPO = new MoneyPO();
moneyPO.setId(20);
moneyPO.setName("jpa 一灰灰 ex");
moneyPO.setMoney(2200L + ((long) (Math.random() * 100)));
moneyPO.setIsDeleted((byte) 0x00);
MoneyPO res = moneyCreateRepository.save(moneyPO);
System.out.println("after insert res: " + res);
}
看下输出结果,惊讶的发现,这个指定id并没有什么卵用,最终db中插入的记录依然是自增的方式来的
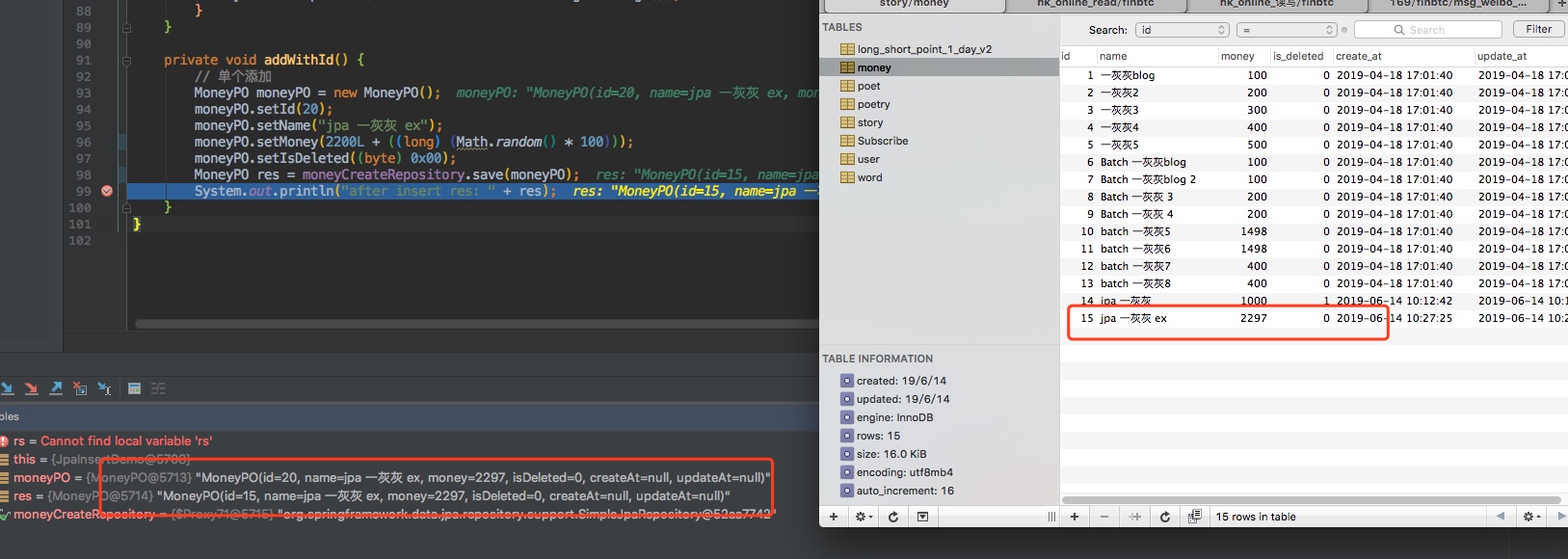
为什么会这样子呢,我们看下sql是怎样的

直接把id给丢了,也就是说我们设置的id不生效,我们知道@GeneratedValue 这个注解指定了id的增长方式,如果我们去掉这个注解会怎样
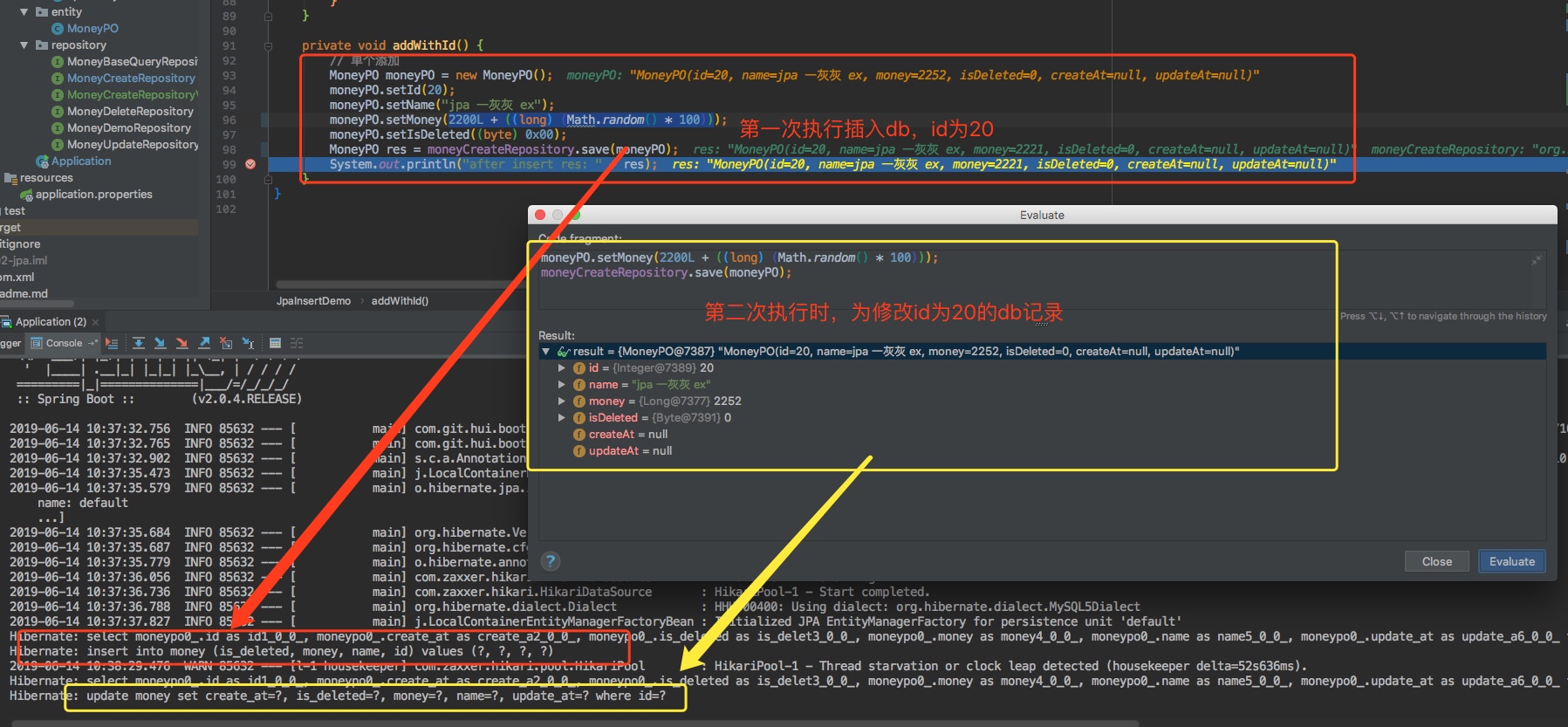
从输出结果来看:
- 如果这个id对应的记录不存在,则新增
- 如果这个id对应的记录存在,则更新
不然这个注解可以主动指定id方式进行插入or修改,那么如果没有这个注解,插入时也不指定id,会怎样呢?
很遗憾的是直接抛异常了,没有这个注解,就必须手动赋值id了

4. 小结
本文主要介绍了下如何使用JPA来实现插入数据,单个or批量插入,也抛出了一些问题,有的给出了回答,有的等待后文继续跟进,下面简单小结一下主要的知识点
- POJO与表关联方式
- 注意几个注解的使用
- 如
@Entity,@Table用于指定这个POJO对应哪张表 - 如
@Column用于POJO的成员变量与表中的列进行关联 - 如
@Id@GeneratedValue来指定主键 - POJO成员变量类型与DB表中列的关系
- db插入的几种姿势
- save 单个插入
- saveAll 批量插入
- 插入时,如要求DO中成员为null时,用mysql默认值,可以使用注解
@DynamicInsert,实现最终拼接部分sql方式插入 - 指定id查询时的几种case
此外本文还留了几个坑没有填
- POJO成员类型与表列类型更灵活的转换怎么玩?
- save 与 saveAndFlush 之间的区别(从命名上,前者保存,可能只保存内存,不一定落库;后者保存并落库,但是没有找到验证他们区别的实例代码,所以先不予评价)
- 注解的更详细使用说明