5.Prometheus大盘配置实战
借助Grafana来实现大盘配置,关于Grafana的启用配置,这里就不详细说明,有兴趣的可以查看前文 * 【中间件】Prometheus实现应用监控 | 一灰灰Blog
接下来主要是针对上一篇 【中间件】Prometheus基于AOP实现埋点采集上报 上报的Histogram数据,来配置一套相对完整的业务监控大盘
I.大盘配置
1. 基本盘选择
直接到官网查找模板大盘,这里选择SpringBoot搭建的服务器项目,可以输入spring关键字进行检索
官网:https://grafana.com/grafana/dashboards?dataSource=prometheus&search=spring
比如我们这里选择 6756 作为基础模板;然后在Grafana上导入
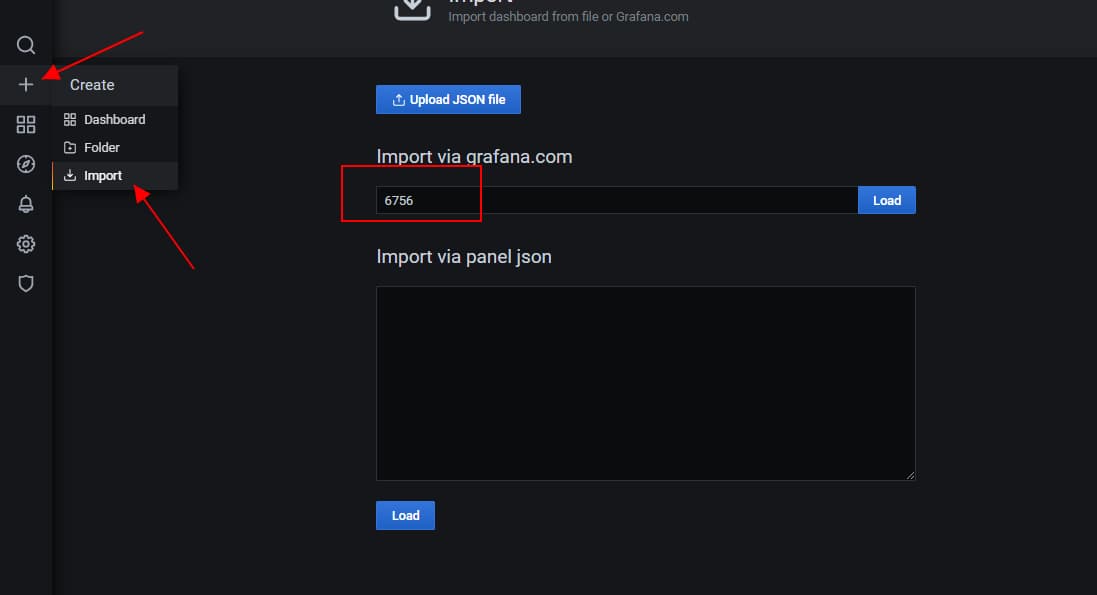
导入之后,对于变量的依赖顺序根据实际情况调整一下,比如我希望第一个变量是application,在选择应用之后,再选择对应的实例ip;
修改步骤如下:
- 依次选择:dashboard settings -> variables
- 将application变量前置到instance前
- application:
- 修改query为:
label_values(jvm_classes_loaded_classes, application)
- 修改query为:
- instance:
- 修改query为:
label_values(jvm_classes_loaded_classes{application="$application"}, instance)
- 修改query为:
- 新增service变量
- query =
label_values(micro_service_histogram_seconds_count{application="$application", instance="$instance"}, service)
- query =
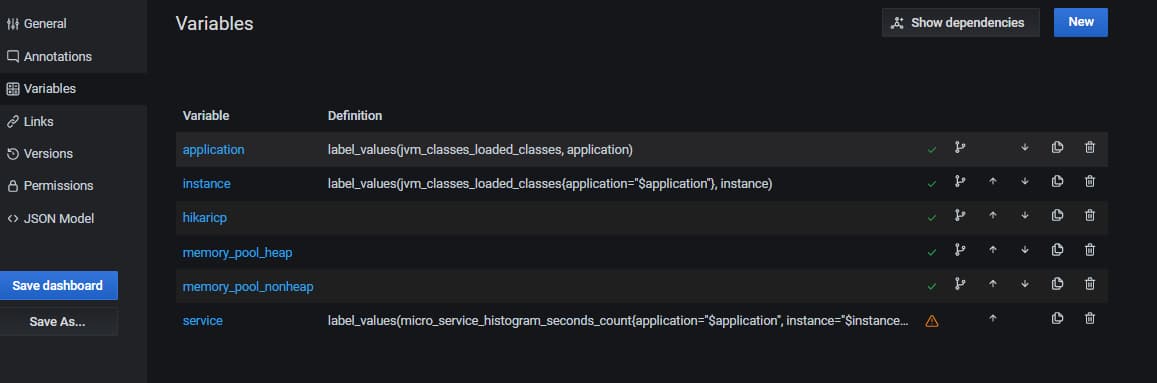
注意
- 一个变量的取值依赖另一个变量,请注意将被依赖的变量顺序放在前面
- 一个变量的取值依赖另一个变量,写法是
metric{tag="$valName"}, 这个变量名前缀是$,且使用双引号包裹 - metric的选择,可以通过直接查看目标服务器的metric接口查看,比如service变量选择的metric就是自定义上报的
micro_service_histogram_seconds_count,而application与instance则选取的是Prometheus-Spring组件上报的spring应用基础信息中的metric
2. 业务盘配置
常见的业务指标,如QPS + RT + TPS + SLA等,接下来看一下如何进行配置
2.1 qps 每秒请求数
主要是借助内置函数rate来计算qps,通过一个计算时间窗口的平均增长速率,来展示接口的qps
(rate(micro_service_histogram_seconds_count{application="$application", instance="$instance", service="$service"}[1m]))
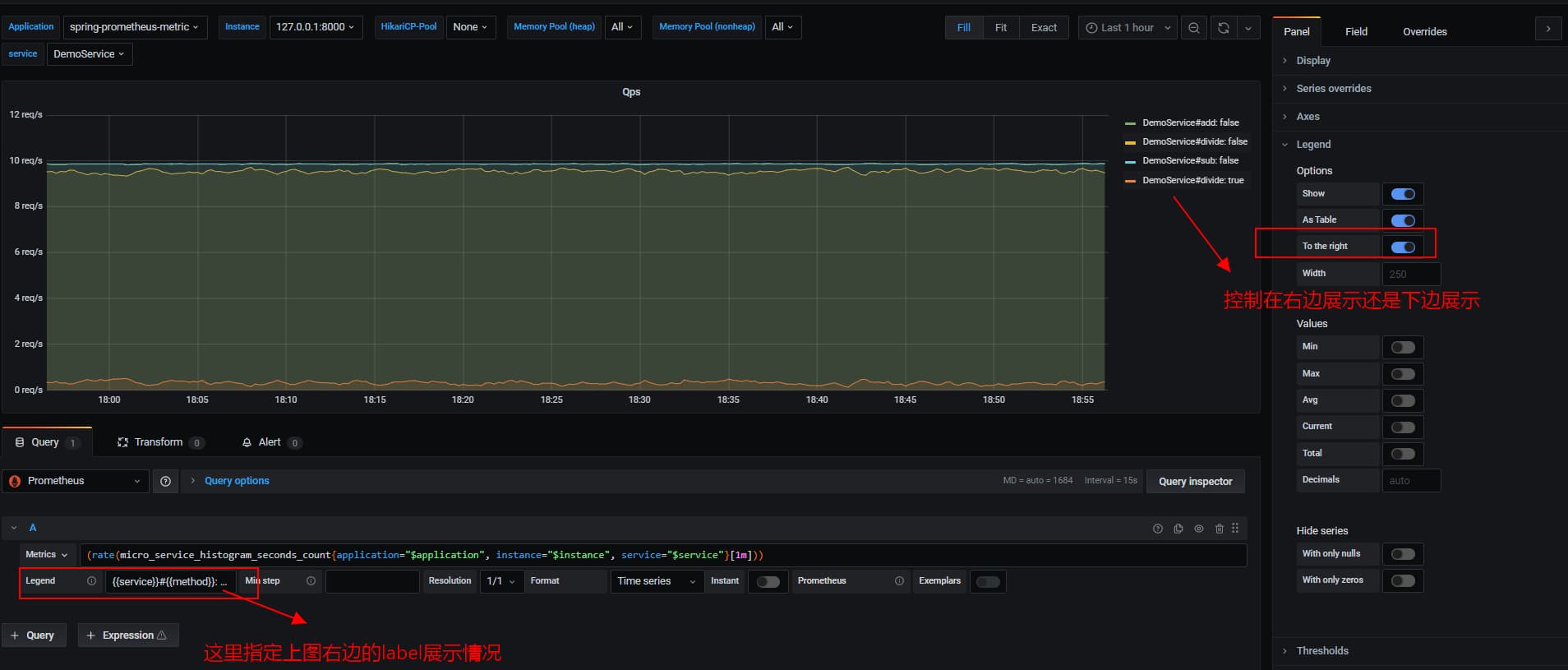
使用rate来计算qps时,会存在一个长尾问题,因为它实际上是根据1min内的所有样本数据,来计算平均增长率,因此当一个时间窗口内,存在瞬时的大数据场景,将不能很好的反应出来
因此更关注瞬时场景时,可以考虑使用irate来代替,它是通过一个时间范围内的区间向量数据中最后两个来计算增长速率的
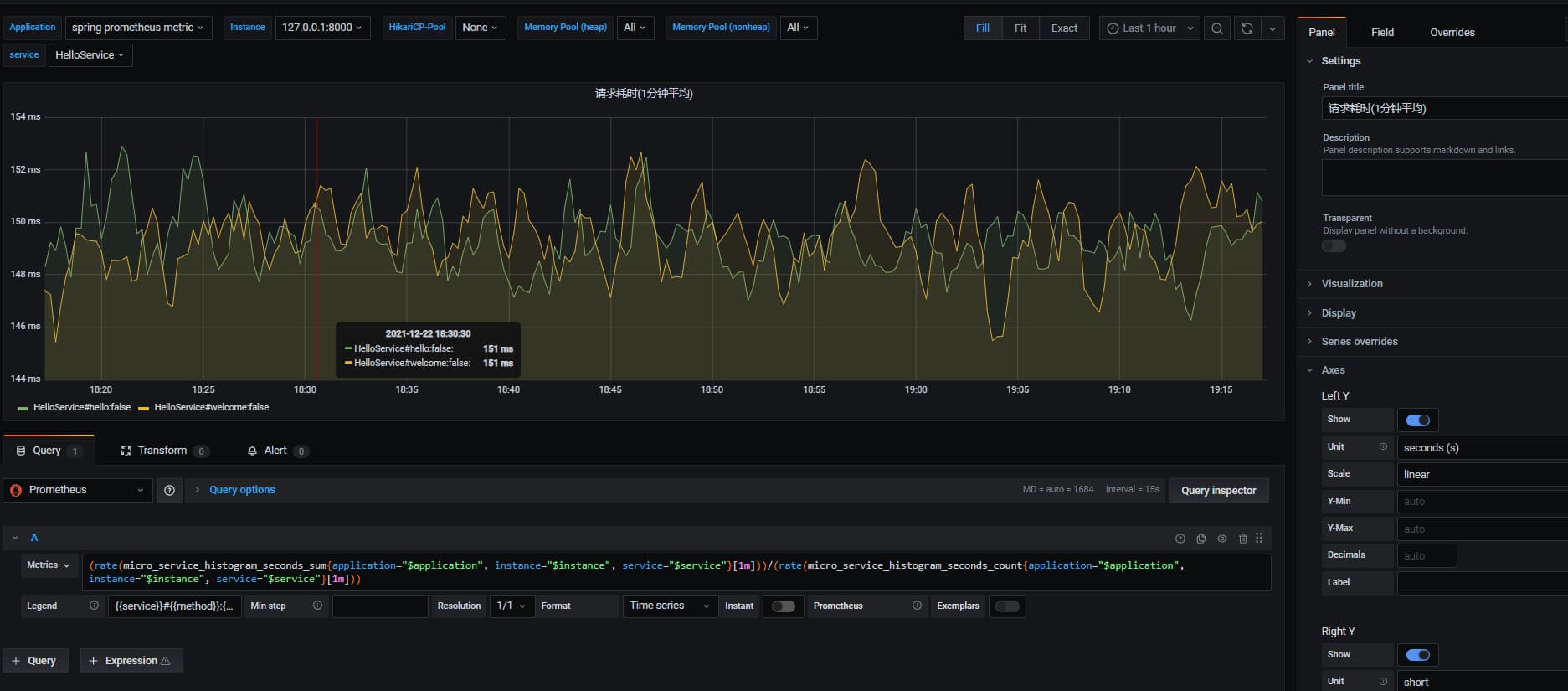
2.2 rt 接口响应平均耗时
对于耗时的统计,也是比较重要的一个指标,用于判断我们系统的响应情况以及性能表现
核心配置: rate(sum / count)
(rate(micro_service_histogram_seconds_sum{application="$application", instance="$instance", service="$service"}[1m]))/(rate(micro_service_histogram_seconds_count{application="$application", instance="$instance", service="$service"}[1m]))
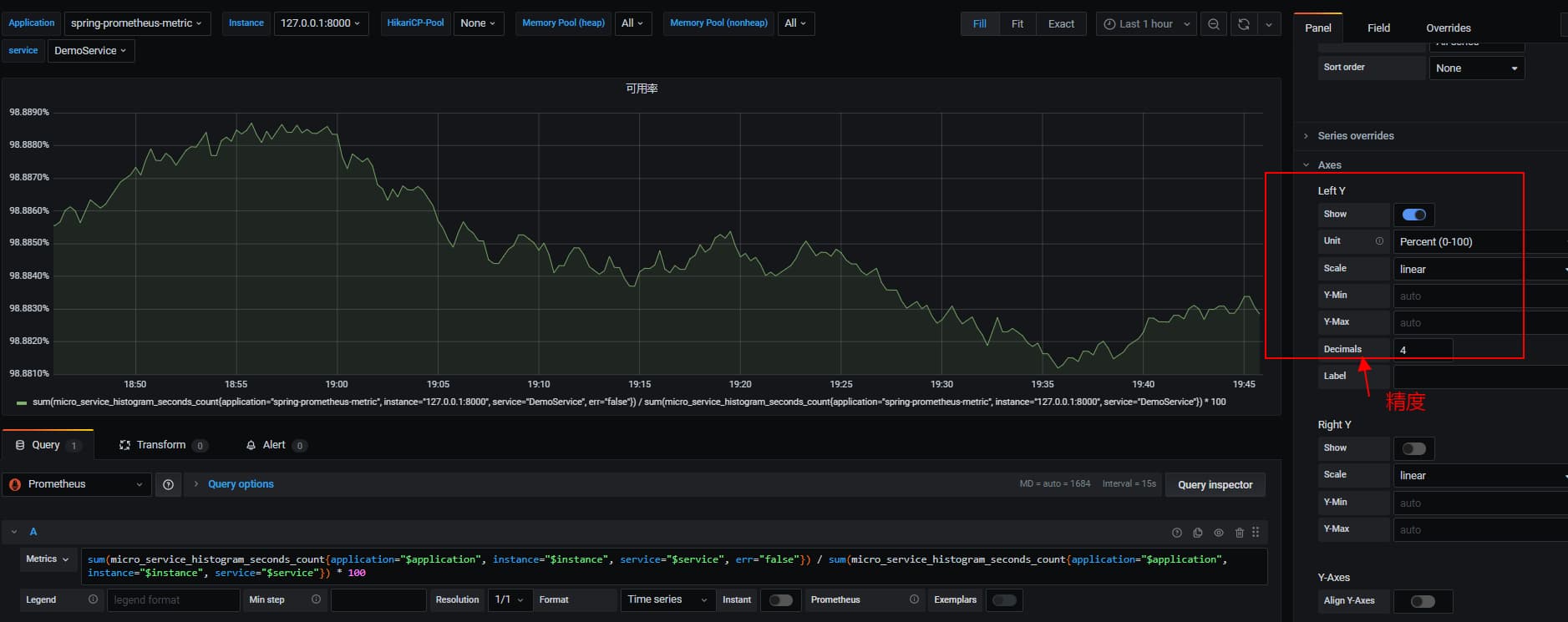
注意Y轴单位选择 seconds
2.3 接口耗时分布统计
基于Histogram样本数据,配合Grafana的热点图来配置耗时统计分布
sum(rate(micro_service_histogram_seconds_bucket{application="$application", instance="$instance", service="$service"}[1m])) by (le)
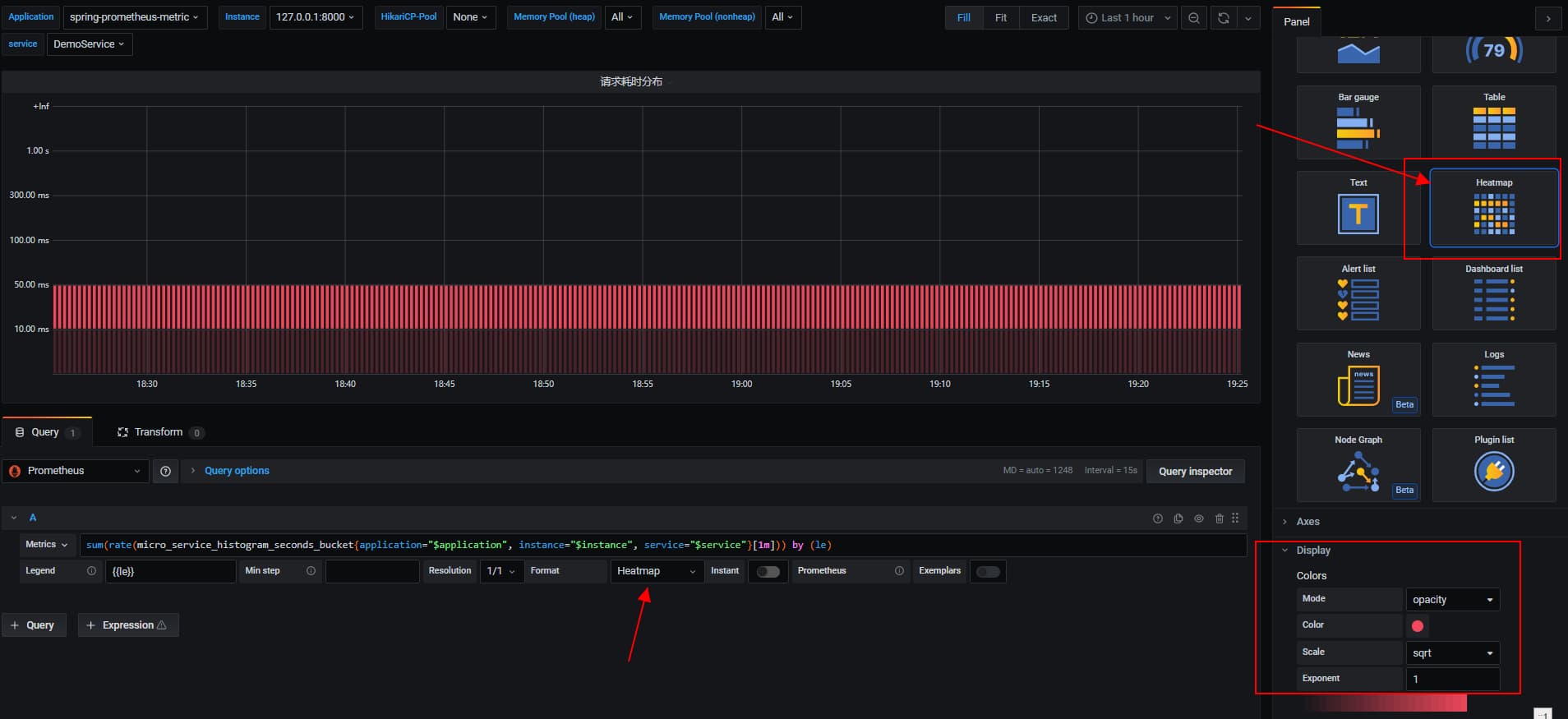
几个关键的配置
- 配置参数中的Format 选择 Heatmap
- 面板的Visualization中,选择 Heatmap
- 面板中的Display,mode选择Opacity
根据颜色的深浅,来判断哪个bucket的请求量较多
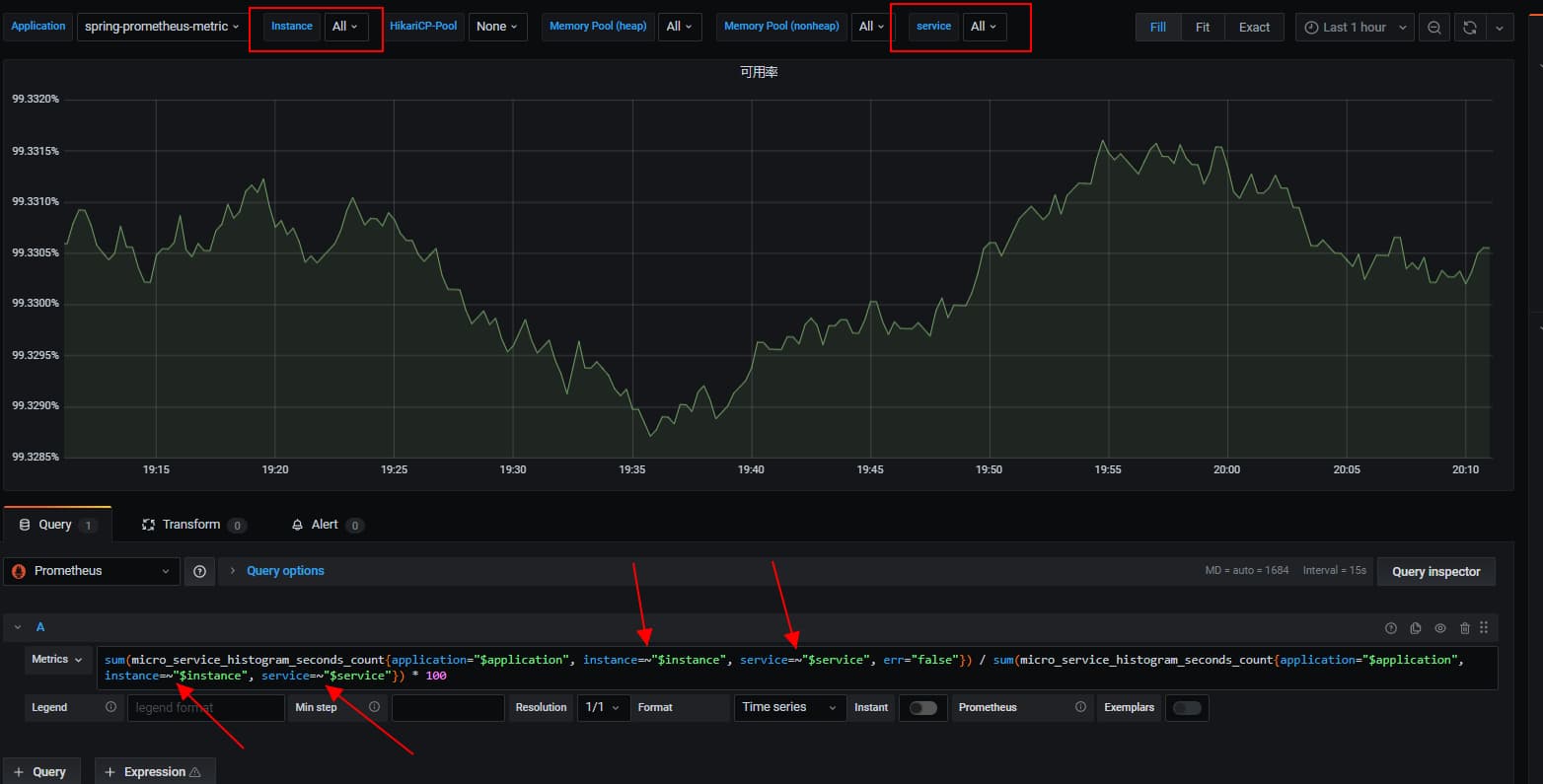
2.4 SLA可用率
根据成功响应的计数 / 总计数来表征接口请求成功率
sum(micro_service_histogram_seconds_count{application="$application", instance="$instance", service="$service", err="false"}) / sum(micro_service_histogram_seconds_count{application="$application", instance="$instance", service="$service"}) * 100
3. 应用维度统计支持
前面的几个配置,统计面板都是基于某个应用,某个实例中的某个方法的维度进行展示,但实际情况是我们也很关注整体应用维度的表现情况
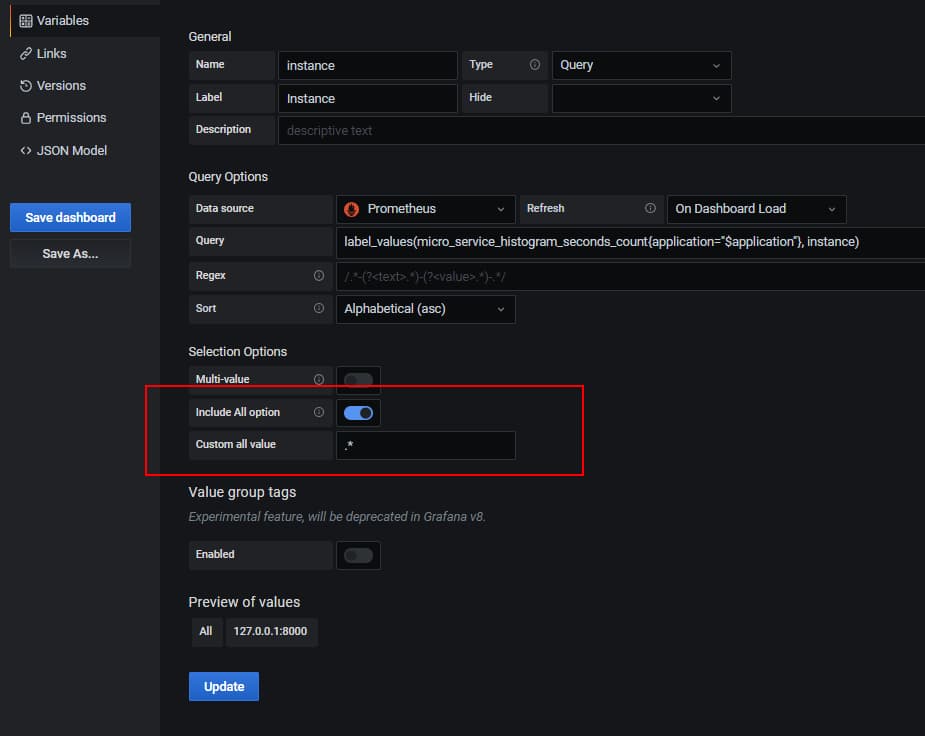
因此我们需要在变量选择中,支持全部
- 开启变量的include all, 并设置
custorm all value = .*
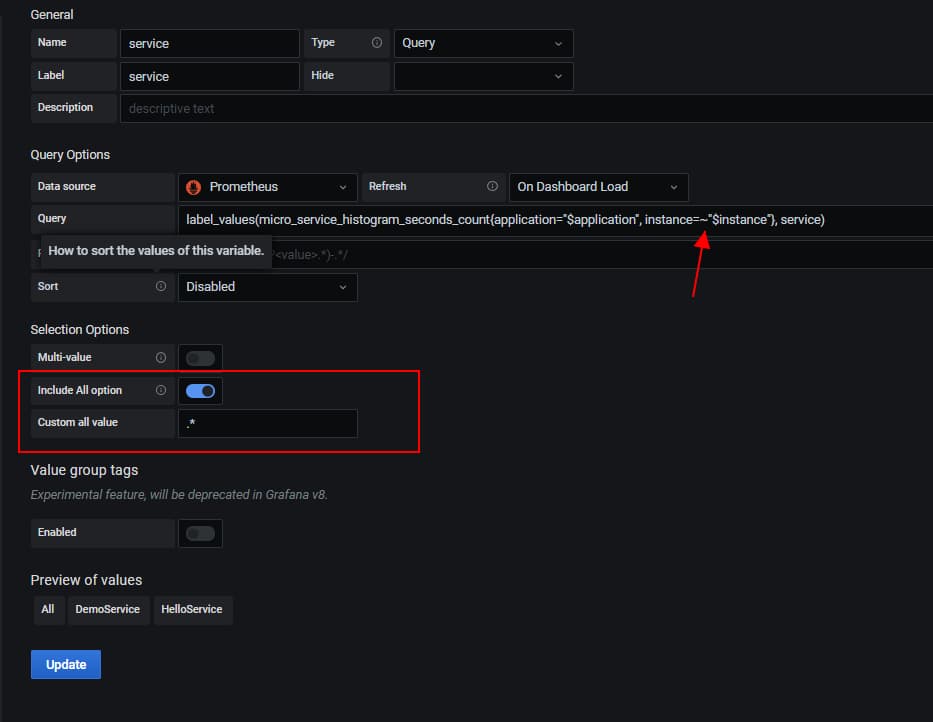
- 第二步就是修改PromQL,将完全匹配调整为正则匹配 (将
=改成=~)
4.小结
本文主要是通过grafana的大盘配置来展示如何使用Prometheus采集的数据,为了更好的使用采集数据,PromQL又是一个无法避免的知识点,下篇博文将带来PromQL的科普
II. 不能错过的源码和相关知识点
0. 项目
- 工程:https://github.com/liuyueyi/spring-boot-demo
- 源码:https://github.com/liuyueyi/spring-boot-demo/tree/master/spring-case/421-prometheus-metric
系列博文:
1. 微信公众号: 一灰灰Blog
尽信书则不如,以上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现bug或者有更好的建议,欢迎批评指正,不吝感激
下面一灰灰的个人博客,记录所有学习和工作中的博文,欢迎大家前去逛逛
- 一灰灰Blog个人博客 https://blog.hhui.top
- 一灰灰Blog-Spring专题博客 http://spring.hhui.top
