03.Agent思考框架-ReAct
1. 背景与起源
ReAct 框架全称为 [Reason + Act: Synergizing Reasoning and Acting in Language Models](https://react-lm.github.io/),由 Yao et al.(2022, Google Research) 首次提出。论文标题为:
这篇论文的出发点非常直接:
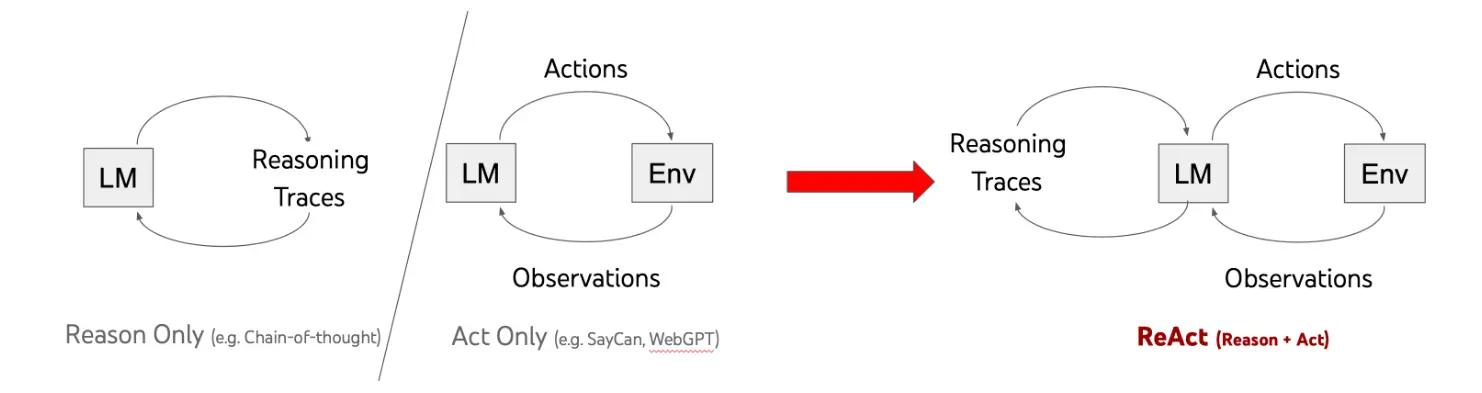
仅靠 Chain-of-Thought(CoT)能让模型“思考”,但不能“行动”; 而仅靠 Tool-use 或 Action-based Agent 能“行动”,但不会“思考”。
ReAct 试图让模型在推理(Reason)与行动(Act)之间交替进行,从而实现真正的智能体行为。
2. 核心思想:让模型在「思考」与「行动」之间循环
传统的 CoT 是静态推理:
输入 → 推理链(CoT) → 答案
而 ReAct 是动态交互式推理:
输入 → 推理步骤(Reason) → 执行动作(Act) → 观察反馈(Observe) → 再推理(Reason) → 再行动(Act) → … → 最终答案
这种循环让模型不只是生成一条思维链,而是能够:
- 主动与外部环境交互(通过工具或接口)
- 根据反馈修正推理路径
- 在多轮循环中完成复杂任务
举个例子如你想查 “北京明天是否适合户外施工”,会先想 “我需要知道明天的天气(推理)→ 打开天气 APP 查数据(行动)→ 看到明天有暴雨(观察)→ 得出‘不适合施工’的结论(再推理)”。 放在大模型 / Agent 场景中,ReAct 就是让模型不再局限于 “纯内部推理”(比如 CoT 只在脑子里想),而是通过 “调用工具、获取外部反馈” 来验证和修正推理,形成闭环:
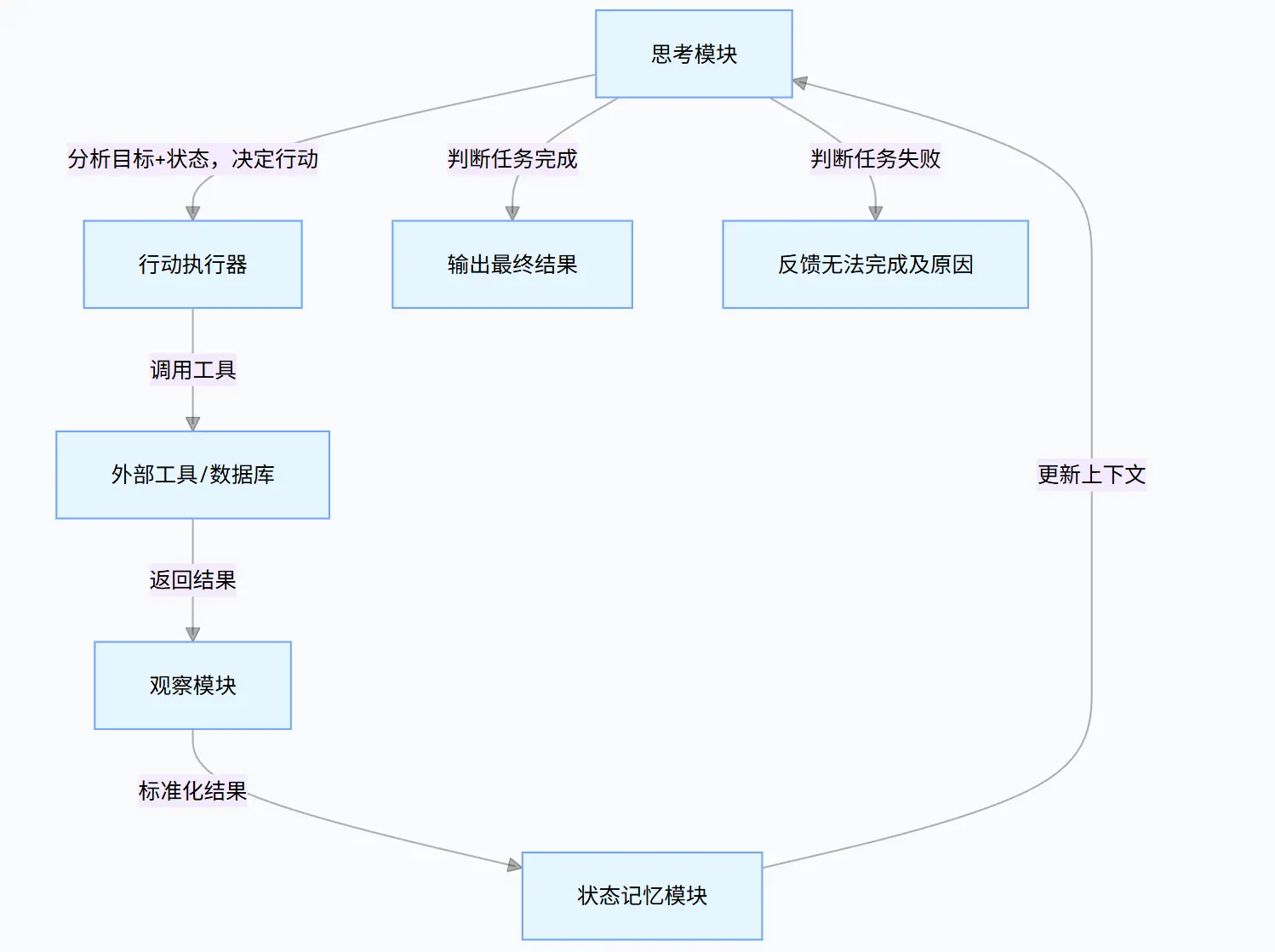
- 推理(Reasoning):分析目标、拆解步骤、决定下一步 “该做什么”(比如 “用户要订建筑材料,我需要先查库存→ 调用库存工具”);
- 行动(Acting):执行具体操作(调用工具 API、查询数据库、发送指令等),是模型与外部世界交互的核心;
- 观察(Observation):获取行动的结果反馈(比如库存工具返回 “钢筋库存充足”“水泥缺货”);
- 迭代:根据观察结果调整推理,直到完成目标(比如水泥缺货→ 推理 “需要找替代供应商”→ 行动 “调用供应商匹配工具”)。
3. ReAct 的机制结构
3.1 核心闭环流程
ReAct 的核心是一个循环式 Prompt 结构,每一轮由 3 个关键组件构成:
| 阶段 | 名称 | 功能 |
|---|---|---|
Reason | 思考步骤 | 模型分析当前状态,推理下一步要做什么 |
Act | 执行动作 | 模型根据推理结果调用外部工具、API、搜索等 |
Observe | 观察反馈 | 模型读取行动结果,更新内部状态 |
循环结构如下:
Question: 谁是2016年的诺贝尔文学奖获得者?
Thought 1: 我需要先查一下2016年诺贝尔文学奖的结果。
Action 1: 搜索("2016 Nobel Prize in Literature winner")
Observation 1: 搜索结果显示是Bob Dylan。
Thought 2: 现在我知道了答案。
Action 2: 回答("2016年诺贝尔文学奖获得者是鲍勃·迪伦。")
这种结构兼具“推理链的透明性”与“可执行性”,是 CoT 向 Agent 推理自然演化的形式。
3.2 关键要素
要想让上面的ReAct的流程跑通,必须满足三个核心条件
- 明确的目标与终止条件:目标要可量化(如2016年、诺贝尔文学奖获得者),终止条件要清晰(找到用户,任务完成)
- 标准化的工具接口:Agent 能 “看懂并调用” 工具(网络搜索)
- 状态记忆模块:Agent 能记录每一轮的 “思考结果、行动内容、观察反馈”,避免重复劳动或者遗忘关键信息
4. 与 CoT 的关系:ReAct = CoT + 行动接口
| 对比维度 | Chain-of-Thought (CoT) | ReAct (推理行动) |
|---|---|---|
| 核心功能 | 静态推理(只思考) | 推理 + 行动 + 反馈循环 |
| 是否交互 | 否(纯语言生成) | 是(能调用外部工具/环境) |
| 信息来源 | 依赖模型训练时的内部知识 | 内部知识 + 外部输入 + 工具反馈数据(调用工具获取) |
| 可解释性 | 高(显式推理链) | 更高(推理+行动全可追溯) |
| 典型应用 | 逻辑推理、数学题 | 工具使用、问答、信息检索、任务规划 |
可以这样理解:
CoT 让模型“会思考”; ReAct 让模型“边思考边行动”。
ReAct 实际上是将 CoT 的“推理链”扩展为一个“推理-行动交替链(Reason–Act Loop)”,使模型能够通过外部信息验证和修正自身推理过程。
5. 典型应用场景
ReAct 框架已成为众多 LLM Agent 框架的基础逻辑,例如:
| 场景 | 示例 |
|---|---|
| 知识检索 Agent | 模型根据推理决定是否调用搜索 API,检索结果再反馈给模型 |
| 任务执行 Agent | 模型通过多轮思考与动作完成复杂流程(如预定行程、分析数据) |
| 工具调用(Tool Use) | ReAct 框架下的模型能自主判断何时调用计算器、数据库或Python执行环境 |
| 多Agent协作 | 多个 Agent 间通过 ReAct 循环共享中间推理结果,实现协同任务(如 AutoGen、LangGraph) |
ReAct 机制也被广泛集成在框架中:
- LangChain / LangGraph:ReAct 是默认的 reasoning template;
- OpenAI GPTs / o1 系列:其系统提示内嵌了类似 ReAct 的隐式结构;
- DeepSeek-R1 / Claude 3.5:均具备“内隐 ReAct”式动态推理循环。
6. ReAct 的优势
| 优势 | 说明 |
|---|---|
| 融合思考与行动 | 不再需要人工编排先“思考”还是“执行”,模型可自动判断何时行动。 |
| 支持闭环反馈 | 环境结果反哺推理过程,形成自我纠错机制。 避免出现纯推理(如CoT)容易出现的“想当然”的错误 |
| 可解释性强 | 每一步 Reason 与 Action 都是可追踪文本,利于调试与评估。 |
| 易扩展 | 可嵌入任意工具调用接口(API、DB、Web 搜索等)。 |
| 增强记忆与规划能力 | 多轮 Reasoning 让模型能规划长序列任务,而非一次性输出。 |
| 通用性强 | ReAct 不依赖特定任务或工具,只要能拆解步骤、调用工具,就能适用:比如从 “查天气” 到 “采购建筑材料”,从 “旅游规划” 到 “科研数据分析”,只需替换工具和目标,框架本身无需修改,开发效率高 |
7. ReAct 的局限与改进方向
| 局限 | 说明 |
|---|---|
| 推理质量依赖模型本身的 CoT 能力 | 若模型的逻辑推理弱,ReAct 仍可能走错路线。 |
| 长上下文管理复杂 | 多轮循环可能导致上下文爆炸,需要 Memory 模块支持。 |
| 计算成本高 | 每轮 Reason + Act + Observe 都是一条完整的 API 调用。 |
| 缺乏全局规划能力 | ReAct 是“逐步决策”,缺乏全局最优策略搜索。 |
因此,后续研究提出了更高阶的扩展框架,如:
- Tree-of-Thought (ToT):将推理链分支化、多路径搜索;
- Reflexion / Self-Refine:在 ReAct 基础上加入“自我反思”机制;
- Graph-of-Thought (GoT):通过图结构管理复杂的推理关系。
这些框架都继承自 ReAct 的核心思想:Reason + Act 的循环推理范式。
8. ReAct在Agent中的具体应用示例
ReAct 是 Agent “编排层” 的核心逻辑,要在 Agent 中落地 ReAct,可以按照 “组件搭建→流程设计→优化迭代” 的三板斧进行套路
8.1 第一步:搭建Agent的ReAct核心组件
前面说了ReAct的三个关键组件: Reason(思考)、Act(行动)、Observe(观察),在具体的Agent实现中,我们还需要额外考虑上下文的管理(Memory)
因此一个Agent要实现ReAct,则应包含下面四个核心模块
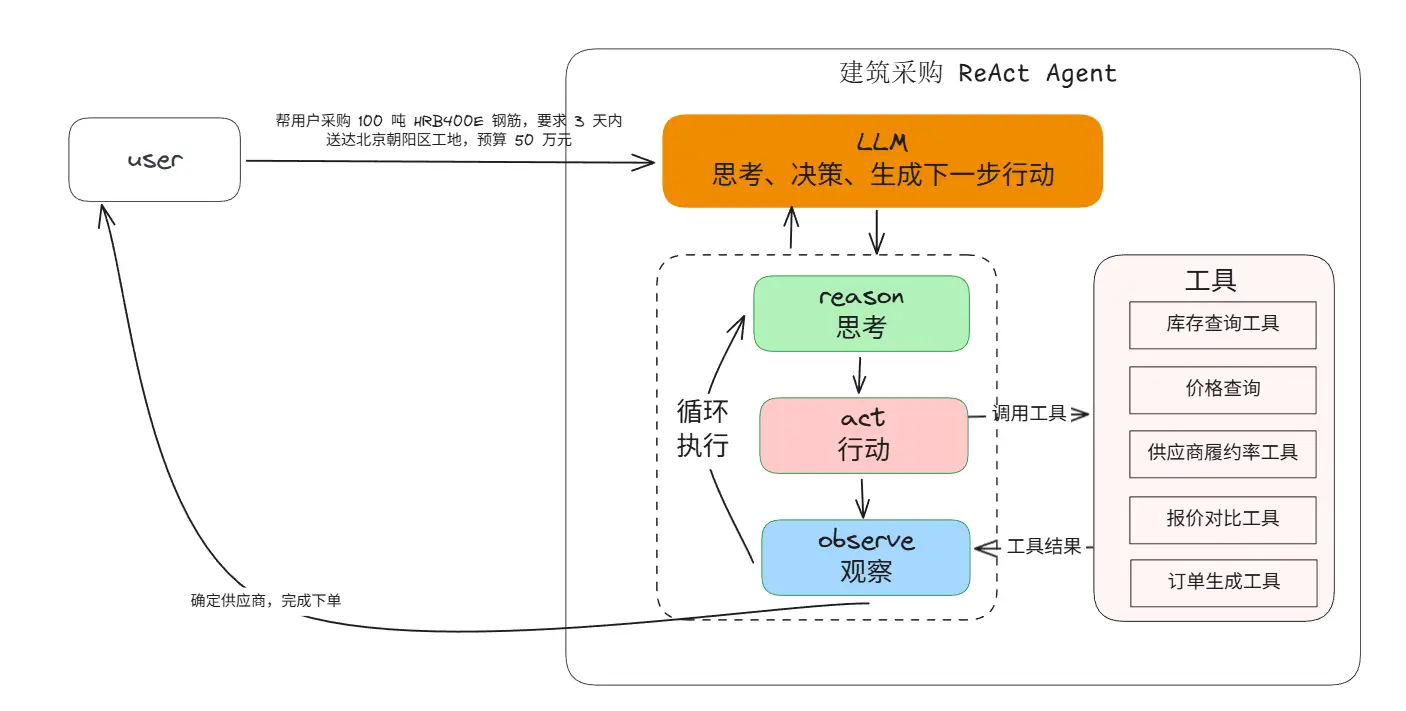
比如我现在给Agent下达一个任务,
帮用户采购 100 吨 HRB400E 钢筋,要求 3 天内送达北京朝阳区工地,预算 50 万元
| 组件 | 功能描述 | 技术实现参照 |
|---|---|---|
| 思考模块(Reasoner) | 接收目标+状态→ 拆解步骤→ 决定下一步行动(比如“调用哪个工具”“参数是什么”) | 基于大模型实现(如GPT-4、Gemini、DeepSeek),通过提示工程引导模型生成“行动指令”(比如“调用库存工具,参数:材料型号=HRB400E,数量=100吨”) |
| 行动执行器(Actor) | 解析思考模块的“行动指令”→ 调用对应的工具(API、数据库、RPA等) | 搭建工具注册中心(统一管理工具名称、输入输出格式),用函数调用(Function Call)实现模型与工具的对接(比如模型输出JSON格式的行动指令,执行器解析后调用API) |
| 观察模块(Observer) | 获取工具返回结果→ 整理成模型能理解的格式(比如把API返回的JSON转成自然语言) | 设计结果标准化模板(比如工具返回“{"supplier":"A","price":3700}"→ 整理为“供应商A的HRB400E钢筋报价3700元/吨”) |
| 状态记忆模块(Memory) | 存储“目标+每一轮的思考/行动/观察结果”→ 为下一轮思考提供上下文 | 用向量数据库(如Milvus、FAISS)存储长上下文,支持“关键词检索”(比如快速查找“供应商A的履约率”) |
8.2 第二步:设计 ReAct 闭环执行流程
依然以上面的建筑材料采购Agent为例
(1)初始化:明确目标与工具
- 目标:用户输入“采购100吨HRB400E钢筋,3天内送达北京朝阳工地,预算50万”;
- 注册工具:库存查询工具、供应商履约率工具、报价对比工具、订单生成工具。
(2)循环执行(直到任务完成/终止)
每一轮的“思考指令”格式示例(模型输出):
{ "action": "调用库存查询工具", "parameters": { "material_type": "HRB400E钢筋", "quantity": 100, "delivery_area": "北京朝阳区", "delivery_time": 3 }, "reason": "需要先确认是否有符合数量、交货期要求的供应商,再对比报价和履约率" }观察模块整理结果示例: “库存查询工具返回3家供应商:1. 供应商A(库存150吨,报价3700元/吨,3天达);2. 供应商B(库存200吨,报价3800元/吨,2天达);3. 供应商C(库存120吨,报价3600元/吨,4天达,超期)”
(3)终止条件设计
- 成功终止:完成目标(如“采购订单提交成功,供应商A将在3天内送达100吨HRB400E钢筋,总价37万元”);
- 失败终止:多次迭代后无法满足目标(如“无符合‘3天达+100吨库存’的供应商,建议延长交货期至4天或更换材料型号”)。
8.3 第三步:优化 ReAct 执行效率
实际应用中,需解决“循环次数过多、工具调用错误、推理冗余”等问题,常用优化技巧:
- ① 工具选择策略:思考模块优先选择“高优先级工具”(比如先查库存,再查履约率,避免跳过关键步骤);
- ② 状态压缩:记忆模块只保留“关键信息”(比如只记“符合条件的供应商A/B”,忽略C的详细信息),减少大模型上下文压力;
- ③ 错误重试机制:行动失败(如工具调用超时、返回错误)时,思考模块自动调整参数(比如“重新调用库存工具,增加‘北京周边供应商’筛选条件”);
- ④ 少样本示例引导:在思考模块的提示中,加入“问题+ReAct循环示例”,让模型更快掌握推理+行动的节奏(比如给一个“采购水泥”的ReAct示例,让模型模仿)。
9. 总结:一句话概括 ReAct
ReAct 是连接“语言模型的思考能力(CoT)”与“Agent 的执行能力”的桥梁。
它让大模型不仅能在语言空间中推理,还能在外部世界中行动;最后再以一张图,来重温一下ReAct