3. 从0到1封装一个通用的耗时统计工具类
接下来本文将再前面的基础耗时工具类的基础之上,从0到1写一个支持多线程场景下的耗时统计工具类
1. 设计思路
1.1 明确思路
首先明确目标:
- 实现一个并发安全的
StopWatch工具类
主要挑战:
- 并发安全
实现思路:
- 参照
StopWatch的实现,解决并发问题
1.2 设计思路
到这里,假定大家已经看过了StopWatch的实现源码(实际上没看过也没啥影响)
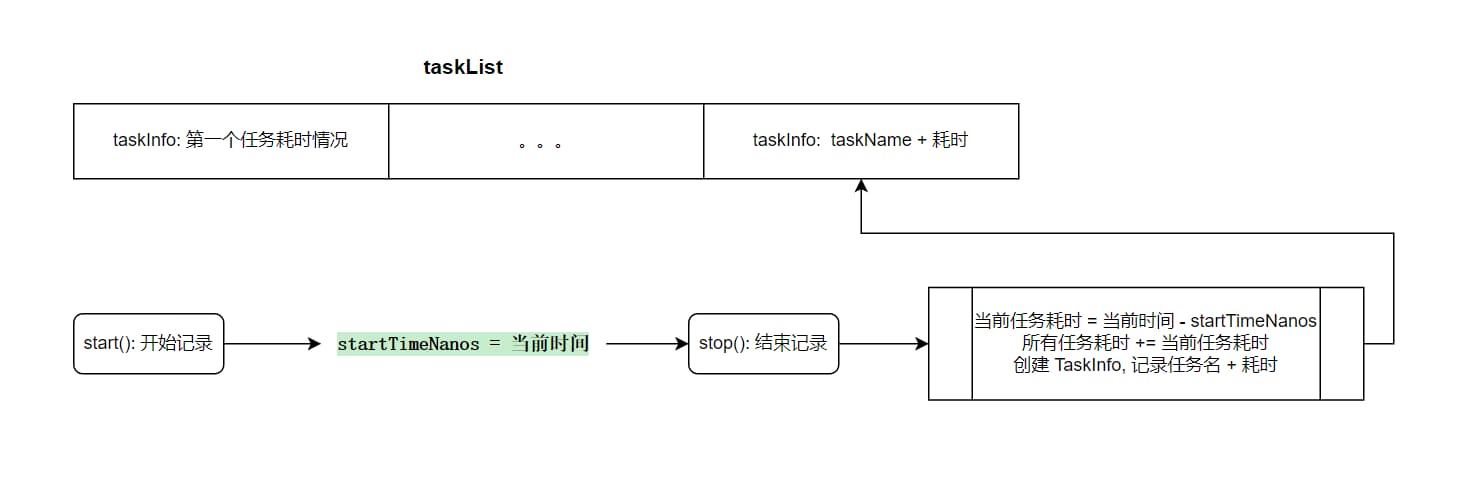
- 在
StopWatch中,通过List<TaskInfo> taskList来记录每个任务的耗时情况 - 因为它主要应用于单线程场景,所以不存在任务的并行耗时记录的场景,通常是要给任务执行完毕,然后开始记录下一个任务,所以在全局使用
startTimeNanos表示当前任务的开始时间,当结束记录时,将任务耗时情况写入taskList列表
基本工作原理如下
从StopWatch的工作原理上,想实现一个并发安全的貌似也不难,我们将List换成Map,支持同时记录多个任务的耗时情况
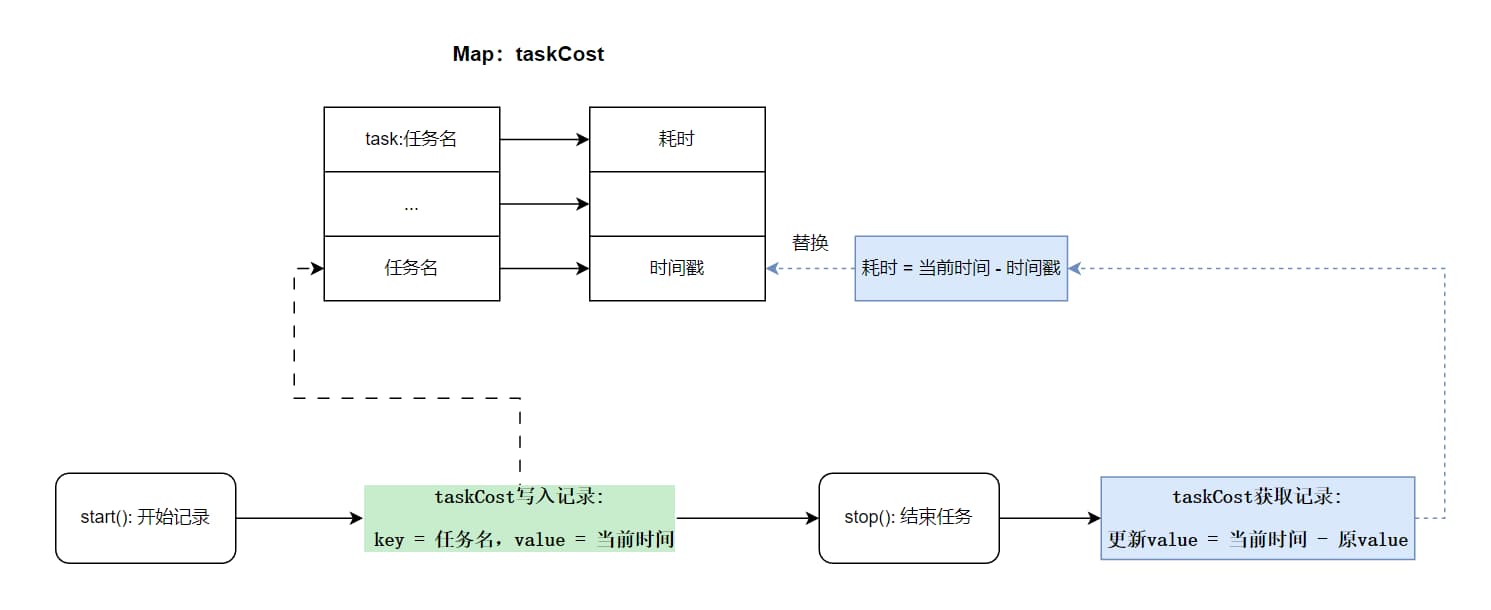
我们的设计上也相对清晰
- 使用一个并发安全的Map容器(如ConcurrentHashMap)来记录任务的耗时情况
- 开始记录一个任务时,向Map中写入
任务名+当前时间戳的键值对 - 结束一个任务时,从Map中获取对应任务的时间戳,与当前时间戳取差值,得到任务的执行耗时,并写回到Map中,这样Map中记录的就是这个任务的耗时时间了
- 耗时分布输出:遍历map,打印结果
2. 实现
2.1 基础实现
下面的源码,可在
com.github.liuyueyi.hhui.trace.test.step.Step3进行查看
接下来我们按照上面的设计思路,现来实现一个Map版本的StopWatch
定义一个工具类 TraceWatch,申明两个核心变量 taskName:总任务名 + taskCost:子任务耗时map
public static class TraceWatch {
/**
* 任务名
*/
private String taskName;
/**
* 子任务耗时时间
*/
private Map<String, Long> taskCost;
public TraceWatch(String taskName) {
this.taskName = taskName;
this.taskCost = new ConcurrentHashMap<>();
}
public TraceWatch() {
this("");
}
}
然后就是实现记录某个任务执行耗时的开始、结束方法
public void start(String task) {
taskCost.put(task, System.currentTimeMillis());
}
public void stop(String task) {
Long last = taskCost.get(task);
if (last == null || last < 946656000L ) {
// last = null -> 兼容没有使用开始,直接调用了结束的场景
// last 存的是耗时而非时间戳 -> 兼容重复调用stop的场景
return;
}
taskCost.put(task, System.currentTimeMillis() - last);
}
最后再实现一个各任务的耗时输出分布 (日志打印基本上验用StopWatch的格式化打印,区别在于这里使用的是毫秒输出)
public void prettyPrint() {
StringBuilder sb = new StringBuilder();
sb.append('\n');
long totalCost = taskCost.values().stream().reduce(0L, Long::sum);
sb.append("TraceWatch '").append(taskName).append("': running time = ").append(totalCost).append(" ms");
sb.append('\n');
if (taskCost.isEmpty()) {
sb.append("No task info kept");
} else {
sb.append("---------------------------------------------\n");
sb.append("ms % Task name\n");
sb.append("---------------------------------------------\n");
NumberFormat pf = NumberFormat.getPercentInstance();
pf.setMinimumIntegerDigits(2);
pf.setMinimumFractionDigits(2);
pf.setGroupingUsed(false);
for (Map.Entry<String, Long> entry : taskCost.entrySet()) {
sb.append(entry.getValue()).append("\t\t");
sb.append(pf.format(entry.getValue() / (double) totalCost)).append("\t\t");
sb.append(entry.getKey()).append("\n");
}
}
System.out.printf("\n---------------------\n%s\n--------------------\n%n", sb);
}
到这里,一个支持多任务耗时并行记录的工具类就实现了,接下来写一个测试用例来验证下效果
private static Random random = new Random();
/**
* 随机睡眠一段时间
*
* @param max
*/
private static void randSleep(String task, int max) {
int sleepMillSecond = random.nextInt(max);
try {
System.out.println(task + "==> 随机休眠 " + sleepMillSecond + "ms");
Thread.sleep(sleepMillSecond);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Test
public void testCost() throws InterruptedException {
TraceWatch traceWatch = new TraceWatch();
traceWatch.start("task1");
randSleep("task1", 200);
traceWatch.stop("task1");
// task2为并行执行任务
new Thread(() -> {
traceWatch.start("task2");
randSleep("task2", 100);
traceWatch.stop("task2");
}).start();
traceWatch.start("task3");
randSleep("task3", 40);
traceWatch.stop("task3");
// task4为并行执行任务
new Thread(() -> {
traceWatch.start("task4");
randSleep("task4", 100);
traceWatch.stop("task4");
}).start();
// 确保所有的任务都执行完毕之后,再输出最终的耗时分布情况
Thread.sleep(100);
traceWatch.prettyPrint();
}
下面是一个示例的输出结果
task1==> 随机休眠 180ms
task3==> 随机休眠 33ms
task2==> 随机休眠 32ms
task4==> 随机休眠 97ms
---------------------
TraceWatch '': running time = 365 ms
---------------------------------------------
ms % Task name
---------------------------------------------
195 53.42% task1
34 09.32% task2
38 10.41% task3
98 26.85% task4
--------------------
从上面的使用demo以及输出,会发现存在一些问题
- 代码的冗余度高
- 总耗时与实际不符(总耗时是每个任务的耗时加和,但是有些任务是并行执行的)
- 最终的结果输出时,得等到所有任务执行完毕,但是上面的实现无法保证这一点
- 耗时统计的代码块抛出异常时,会导致无法正确记录耗时情况(即stop方法要求业务方确保和start一起出现,一定会被调用到)
2.2 使用姿势优化
接下来我们尝试解决提出的问题,首先是使用姿势的优化,提供一个耗时的封装
在前面的基础上,新增一个无返回/有返回的方法
public void cost(Runnable run, String task) {
try {
start(task);
run.run();
} finally {
stop(task);
}
}
public <T> T cost(Supplier<T> sup, String task) {
try {
start(task);
return sup.get();
} finally {
stop(task);
}
}
然后,我们再借助try语句来实现自动的耗时输出, 再结果打印时,我们遍历一下所有的任务,看一下是否已经执行完毕(通过判断taskCost中存的是时间戳还是耗时来判断任务是否执行完毕,当然也是可以新增一个状态来判断任务是否已执行完)
public class TraceWatch implements Closeable {
/**
* 等待所有的任务执行完毕
*/
public void allExecuted() {
while (true) {
boolean hasTaskRun = false;
for (Long val: taskCost.values()) {
if (val > 9466560000L) {
// 存的是毫秒时间戳, 表示还有任务没有执行完毕,自旋等一会
hasTaskRun = true;
break;
}
}
if (hasTaskRun) {
try {
// 自选等待
Thread.sleep(5);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
} else {
break;
}
}
}
@Override
public void close() throws IOException {
prettyPrint();
}
}
接下来再看一下新的使用姿势
@Test
public void testCost2() throws InterruptedException {
try (TraceWatch traceWatch = new TraceWatch()) {
traceWatch.cost(() -> randSleep("task1", 200), "task1");
new Thread(() -> { traceWatch.cost(() -> randSleep("task2", 100), "task2"); }).start();
traceWatch.cost(() -> randSleep("task3", 40), "task3");
new Thread(() -> {
String ans = traceWatch.cost(() -> {
randSleep("task4", 100);
return "ok";
}, "task4");
System.out.println("task4 返回" + ans);
}).start();
}
}
整体来说,相比较于前面的版本,使用侧还是要简单明了不少的。 但是请注意,再实际使用的过程中,可能会出现最后一个 task4 耗时统计异常的情况,如下
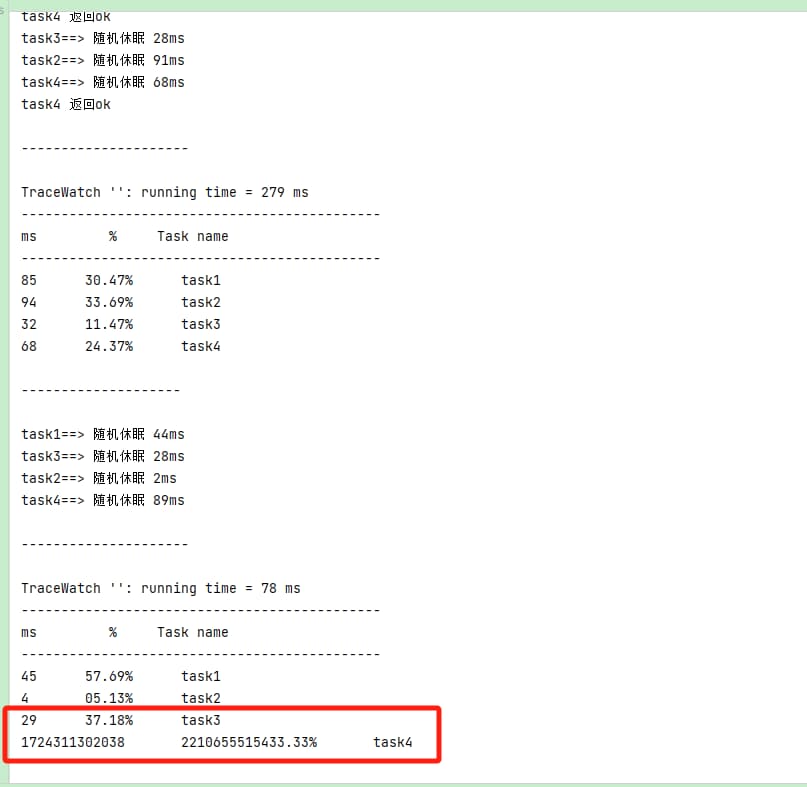
为什么会出现这种情况呢? 我们在耗时输出时,不是已经做了一个自旋等待所有任务执行完毕么,为啥还会出现任务没有执行完毕的情况呢?
这里主要的原因在于并行的场景下,TraceWatch 的 close 方法执行过程中,allExecuted 这个方法执行完了之后,而在 prettyPrint 打印前,上面的task4这个任务执行了start()方法开始了耗时记录,从而导致出现上面的问题
2.3 并发优化
接下来我们再优化一下上面的工具类,除了解决上面的问题之外,我们再调整一下整体耗时的规则,记录从TraceWatch初始化,到最终耗时输出这个时间段的耗时,作为整体的耗时记录(取代之前的所有的单个任务耗时加和作为总耗时)
- 新增
markExecuteOver标记是否所有的任务执行完毕 - 若所有任务执行完毕,则不再支持新的任务耗时记录
- 对象创建时,作为整体任务的开始时间; 日志打印/close方法触发时,作为整体任务执行结束时间
添加上面三个逻辑之后,新的工具类如下
public class TraceWatch implements Closeable {
/**
* 任务名
*/
private String taskName;
/**
* 子任务耗时时间
*/
private Map<String, Long> taskCost;
/**
* 用于标记是否所有的任务执行完毕
* 执行完毕之后,不在支持继续添加记录
*/
private volatile boolean markExecuteOver;
public TraceWatch(String taskName) {
this.taskName = taskName;
this.taskCost = new ConcurrentHashMap<>();
markExecuteOver = false;
start(taskName);
}
public TraceWatch() {
this("");
}
public void cost(Runnable run, String task) {
try {
start(task);
run.run();
} finally {
stop(task);
}
}
public <T> T cost(Supplier<T> sup, String task) {
try {
start(task);
return sup.get();
} finally {
stop(task);
}
}
// 开始记录耗时,不给外部使用,主要是避免使用者忘记了调用 stop 方法,导致 allExecuted 陷入死循环问题
private void start(String task) {
if (markExecuteOver) {
System.out.println("所有耗时记录已结束,忽略 " + task);
return;
}
taskCost.put(task, System.currentTimeMillis());
}
private void stop(String task) {
Long last = taskCost.get(task);
if (last == null || last < 946656000L) {
// last = null -> 兼容没有使用开始,直接调用了结束的场景
// last 存的是耗时而非时间戳 -> 兼容重复调用stop的场景
return;
}
taskCost.put(task, System.currentTimeMillis() - last);
}
public void prettyPrint() {
if (markExecuteOver) {
// 未执行完毕,则等待所有的任务执行完毕
stop(this.taskName);
allExecuted();
}
StringBuilder sb = new StringBuilder();
sb.append('\n');
long totalCost = taskCost.remove(this.taskName);
sb.append("TraceWatch '").append(taskName).append("': running time = ").append(totalCost).append(" ms");
sb.append('\n');
if (taskCost.isEmpty()) {
sb.append("No task info kept");
} else {
sb.append("---------------------------------------------\n");
sb.append("ms % Task name\n");
sb.append("---------------------------------------------\n");
NumberFormat pf = NumberFormat.getPercentInstance();
pf.setMinimumIntegerDigits(2);
pf.setMinimumFractionDigits(2);
pf.setGroupingUsed(false);
for (Map.Entry<String, Long> entry : taskCost.entrySet()) {
sb.append(entry.getValue()).append("\t\t");
sb.append(pf.format(entry.getValue() / (double) totalCost)).append("\t\t");
sb.append(entry.getKey()).append("\n");
}
}
// 若项目中没有Slfj4的实现,则直接使用标准输出
System.out.printf("\n---------------------\n%s\n--------------------\n%n", sb);
}
/**
* 等待所有的任务执行完毕
*/
public void allExecuted() {
while (true) {
boolean hasTaskRun = false;
for (Long val : taskCost.values()) {
if (val > 946656000L) {
// 表示还有任务没有执行完毕,自旋等一会
hasTaskRun = true;
break;
}
}
if (hasTaskRun) {
try {
Thread.sleep(5);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
} else {
break;
}
}
markExecuteOver = true;
}
@Override
public void close() {
stop(this.taskName);
// 等待所有任务执行完毕
allExecuted();
prettyPrint();
}
}
对应的使用姿势基本上与前面没什么差别,我们新增一个没有被traceWatch.cost包裹的代码块,验证下新的工具类
@Test
public void testCost3() {
long start = System.currentTimeMillis();
try (TraceWatch traceWatch = new TraceWatch()) {
randSleep("前置",20);
traceWatch.cost(() -> randSleep("task1", 200), "task1");
new Thread(() -> {
traceWatch.cost(() -> randSleep("task2", 100), "task2");
}).start();
traceWatch.cost(() -> randSleep("task3", 40), "task3");
new Thread(() -> {
String ans = traceWatch.cost(() -> {
randSleep("task4", 100);
return "ok";
}, "task4");
System.out.println("task4 返回" + ans);
}).start();
}
long end = System.currentTimeMillis();
System.out.println("整体耗时 = " + (end - start));
}
多执行几次,将会看到下面这类的输出

重点注意几个关键输出:
- task4 耗时记录被忽略了,即出现了先执行
allExecuted(),后统计task4耗时的场景 整体耗时(147ms)约等于前置(12ms)+task1(106ms)+task3(27ms)
因为task2是异步执行的,它可以与task1/3并行执行,所以对整体的耗时基本没有影响,这里的整体耗时输出和我们外层直接统计的耗时输出基本一致,表明这个整体的耗时输出结果是符合真实预期的
2.4 小结
本文通过一步一步的实现 + 复盘,得出了一个简单的、适用于并发场景下的耗时分布统计工具类。再实现的过程中,给出了为什么最终的成品长这样,因为什么原因,引入了xx成员变量,解决了什么问题,通过将这个工具类的实现步骤拆分,给大家演示了一下一个相对成熟的工具类的迭代过程
知识点
接下来我们对整体的实现,从技术侧做一个小结,相关的知识点有:
- 并发任务耗时支持: 借助
ConcurrentHashMap来记录每个任务的耗时情况 - 通过函数方法,封装代码块的耗时统计使用姿势,确保
start与stop一定会配套出现 - 自旋等待的方式,等待所有的任务执行完毕之后,再输出耗时分布
- 全局结束标记,当标记结束之后,不再支持新的任务耗时统计(注意
markExecuteOver前面的修饰volatile)
缺陷点
然后我们再看一下这个工具类的缺陷:
- 代码侵入性问题(依然时需要再业务代码侧进行埋点)
- 任务名相同时,会出现耗时覆盖
- 任务耗时百分比加和不是100%(因为异步任务以及任务之外的代码块执行耗时的影响,导致占比一般不是100%了)
待优化点
在上面这个工具类的基础上,我们还有什么可以优化的地方么?
- 简化异步代码块的耗时统计,看是否可以直接将异步的能力集成在工具类中,减小业务侧异步支持的成本
本文所有代码均可以在 trace-watch-dog 获取