十:文档 Document 查询高级篇
上一篇的mongodb查询,主要介绍的是一些基本操作,当然有基本就高阶操作;
本文将带来更多的查询姿势
- 排序
- 分页
- 聚合
1. 排序
在mongodb中,使用sort方法进行排序,语法如下
db.collection.find().sort({key: 1})
请注意,sort内部是一个对象,key为field,value为1或者-1,其中1表示升序,-1表示降序
实例说明,根据age进行排序
db.doc_demo.find().sort({'age': 1})
输出如下:

上面的演示属于常规的操作,但是针对mongodb的特点,自然会有一些疑问
q1: 如果某个文档没有包含这个field,排序是怎样的?
db.doc_demo.find().sort({'tag': 1})
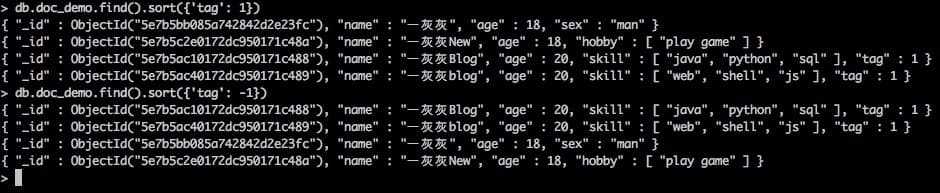
从输出来看,升序时,不包含这个field的文档,在最前面;降序时,不包含这个field的文档,在最后面
q2: 支持多个field排序吗?
原则上一般不建议多个field的排序(比较影响性能),但对于数据库而言,你得支持吧
# 在开始之前,先改一下tag,让文档不完全一致
db.doc_demo.update({"_id": ObjectId("5e7b5ac10172dc950171c488")}, {$set: {'tag': 2}})
db.doc_demo.update({"_id": ObjectId("5e7b5bb085a742842d2e23fc")}, {$set: {'tag': 2}})
# 先根据age进行升序排,当age相同的,根据tag降序排
db.doc_demo.find().sort({'age': 1, 'tag': -1})
# 先根据tag进行升序排,tag相同的,根据age升序排
db.doc_demo.find().sort({'tag': 1, 'age': 1})

请注意上的输出,在涉及到多个field排序时,优先根据第一个进行排序,当文档的field相同时,再根据后面的进行排序
2. 分页
当文档很多时,我们不可能把所有的文档一次返回,所以就有了常见的分页,在sql中我们一般使用limit offset来实现分页,在mongodb中也差不多
limit()
限制返回的文档数
db.doc_demo.find().limit(2)

skip()
使用limit进行返回条数限制,使用skip进行分页,表示跳过前面的n条数据
# 跳过第一条数据,返回两条; 相当于返回第2、3条数据
db.doc_demo.find().limit(2).skip(1)

3. 聚合
使用aggregate()来实现聚合,用于处理求和、平均值,最大值,分组等
数据准备:
{ "_id" : ObjectId("5e7b5ac10172dc950171c488"), "name" : "一灰灰blog", "age" : "19", "skill" : [ "java", "python", "sql" ], "tag" : 2 }
{ "_id" : ObjectId("5e7b5ac40172dc950171c489"), "name" : "一灰灰blog", "age" : 20, "skill" : [ "web", "shell", "js" ], "tag" : 1 }
{ "_id" : ObjectId("5e7b5bb085a742842d2e23fc"), "name" : "一灰灰", "age" : 18, "sex" : "man", "tag" : 2 }
{ "_id" : ObjectId("5e7b5c2e0172dc950171c48a"), "name" : "一灰灰", "age" : 18, "hobby" : [ "play game" ] }
分组查询
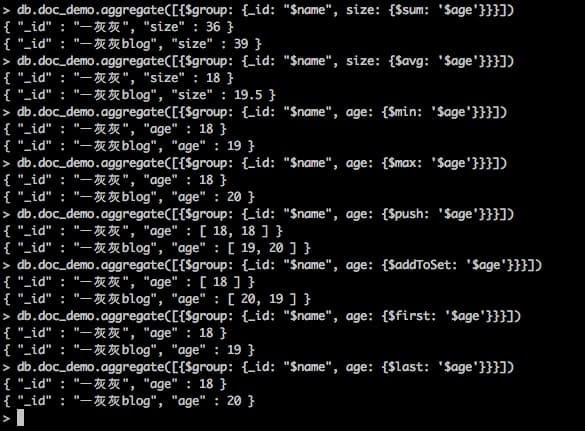
根据name进行分组统计
# 根据name进行分组,统计文档数量
# 相当于sql中的 select name, count(1) from doc_demo group by name
db.doc_demo.aggregate([{$group: {_id: "$name", size: {$sum: 1}}}])

请注意,分组的条件中
_id: 表示根据哪个字段进行分组size: {}: 表示聚合条件指定,将结果输出到名为size的field中filed名前加$进行指定
当前mongodb支持的聚合表达式包括:
| 表达式 | 说明 | 举例说明 |
|---|---|---|
| sum | 求和 | db.doc_demo.aggregate([{$group: {_id: "$name", size: {$sum: '$age'}}}]) |
| avg | 平均值 | db.doc_demo.aggregate([{$group: {_id: "$name", size: {$avg: '$age'}}}]) |
| min | 取最小 | db.doc_demo.aggregate([{$group: {_id: "$name", age: {$min: '$age'}}}]) |
| max | 取最大 | db.doc_demo.aggregate([{$group: {_id: "$name", age: {$max: '$age'}}}]) |
| push | 结果插入到一个数组中 | db.doc_demo.aggregate([{$group: {_id: "$name", age: {$push: '$age'}}}]) |
| addToSet | 结果插入集合,过滤重复 | db.doc_demo.aggregate([{$group: {_id: "$name", age: {$addToSet: '$age'}}}]) |
| first | 第一个 | db.doc_demo.aggregate([{$group: {_id: "$name", age: {$first: '$age'}}}]) |
| last | 最后一个 | db.doc_demo.aggregate([{$group: {_id: "$name", age: {$last: '$age'}}}]) |
上面虽然介绍了分组支持的一些表达式,但是没有查询条件,难道只能针对所有的文档进行分组统计么?
分组过滤
借助$match来实现过滤统计,如下
db.doc_demo.aggregate([
{$match: {'tag': {$gt: 1}}},
{$group: {_id: '$name', age: {$sum: 1}}}
])

请注意,$match的语法规则和find的查询条件一样,会将满足条件的数据传递给后面的分组计算
这种方式和liux中的管道特别相似,aggregate方法的参数数组中,前面的执行完毕之后,将结果传递给后面的继续执行,除了$match和$group之外,还有一些其他的操作
| 操作 | 说明 |
|---|---|
| $project | 修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。 |
| $match | 用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。 |
| $limit | 用来限制MongoDB聚合管道返回的文档数。 |
| $skip | 在聚合管道中跳过指定数量的文档,并返回余下的文档。 |
| $unwind | 将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。 |
| $group | 将集合中的文档分组,可用于统计结果。 |
| $sort | 将输入文档排序后输出。 |
| $geoNear | 输出接近某一地理位置的有序文档。 |